Detecting changes in JavaScript and CSS isn't an easy task, Part 1

Hello!
In a previous post, I explained the idea behind tracking the JavaScript and CSS resources loaded by a web page in Secutils.dev and who benefits from it. I had originally hoped to ship the feature as part of the "Q2 2023 - Apr-Jun" update, but it took noticeably longer than I thought. In this post (and the next two) I want to walk through why comparing JavaScript and CSS files between two snapshots of a web page is much harder than it looks, and what design choices made the feature work for Secutils.dev.
Two important pieces of context have changed since this post:
- The "Resources Tracker" described here was unified with the later "Content Tracker" into a single Page tracker feature. There is also a separate API tracker for tracking arbitrary HTTP API responses.
- Scraping and scheduling moved into the standalone Retrack project (now a git submodule at
components/retrack). The example file path used to besecutils-dev/secutils-web-scraper/.../execute.ts; today it lives inretrack-web-scraper.
The challenges below all still apply, in fact several of them shaped the decision to extract Retrack as a reusable component.
Problem statement
As a web application developer, you want to know that your deployed application loads only the JavaScript and CSS you intended. Unintended changes (broken pipeline, malicious activity, unexpected third-party update) should surface as soon as possible.
As a security researcher, you have the same need from the other side: knowing when a third-party application's resources change is a strong hint that it was upgraded, and that there might be new bugs to look at.
Either way, the goal is the same: capture the set of JavaScript and CSS resources a page loads, store enough to detect future changes, and notify the right person when those changes happen.
That sounds simple. It isn't.
Challenge 1: Inline and external resources
Modern pages mix inline and external resources. Inline resources are embedded directly in the HTML (<script>...</script>, <style>...</style>); external resources are referenced by URL and fetched separately:
<!DOCTYPE html>
<html lang="en">
<head>
<script src="./i-am-external-javascript-resource.js"></script>
<link href="./i-am-external-css-resource.css" rel="stylesheet" />
<script>alert('I am an inline JavaScript resource!');</script>
<style>
a::before {
content: 'I am an inline CSS resource!';
}
</style>
</head>
<body>Hello World</body>
</html>
Fetching the static HTML and parsing it is not enough, you also need to fetch every external resource the page references. That adds some work, but it's still routine web scraping. So far so good.
Challenge 2: Dynamically loaded resources
The much bigger problem is that JavaScript can load (or generate) more JavaScript and CSS at runtime, and CSS can @import further CSS. To capture that, you can't just parse the HTML: you have to execute the page the way a browser does.
Mature high-level libraries help here. The two obvious choices are Puppeteer and Playwright. I picked Playwright for Secutils.dev. Playwright lets us:
- Drive a real Chromium browser, so dynamic loading and modern JS APIs just work.
- Use
page.evaluate()to run code in the page context to discover inline resources. - Use
page.on('response', ...)to intercept every external resource the page loads, no matter when in the lifecycle it loads.
The core of the Retrack scraper looks like this (full source in retrack-web-scraper):
const page = await browser.newPage();
page.on('response', async (response) => {
const resourceType = response.request().resourceType() as 'script' | 'stylesheet';
if (resourceType !== 'script' && resourceType !== 'stylesheet') {
return;
}
const externalResourceContent = await response.body();
// ...record/process the resource...
});
await page.goto(url, { waitUntil: 'domcontentloaded', timeout });
const inlineResources = await page.evaluate(async () => {
for (const script of Array.from(document.querySelectorAll('script'))) {
// ...extract inline JavaScript...
}
for (const style of Array.from(document.querySelectorAll('style'))) {
// ...extract inline CSS...
}
// ...
});
It is not overwhelmingly complex, which is great.
A real browser is resource-intensive, and pointing it at arbitrary user-supplied URLs has obvious security implications. That is why Secutils.dev runs the scraper as a separate service: today as the Retrack Web Scraper (Node.js + Chromium, port 7272), deployed in its own container with strict resource limits. The full security story is in Running web scraping service securely.
Challenge 3: Large resources
Once we've discovered every inline and external resource, how do we detect changes? The simplest answer is "store and diff the content". The problem is that web pages are heavy. According to the Web Almanac 2022 page-weight chapter, the median desktop page loads roughly 1,026 KB of images, 509 KB of JavaScript, 72 KB of CSS, and 31 KB of HTML. Mobile is similar. With Secutils.dev storing multiple revisions per tracker, full-content storage gets expensive fast.
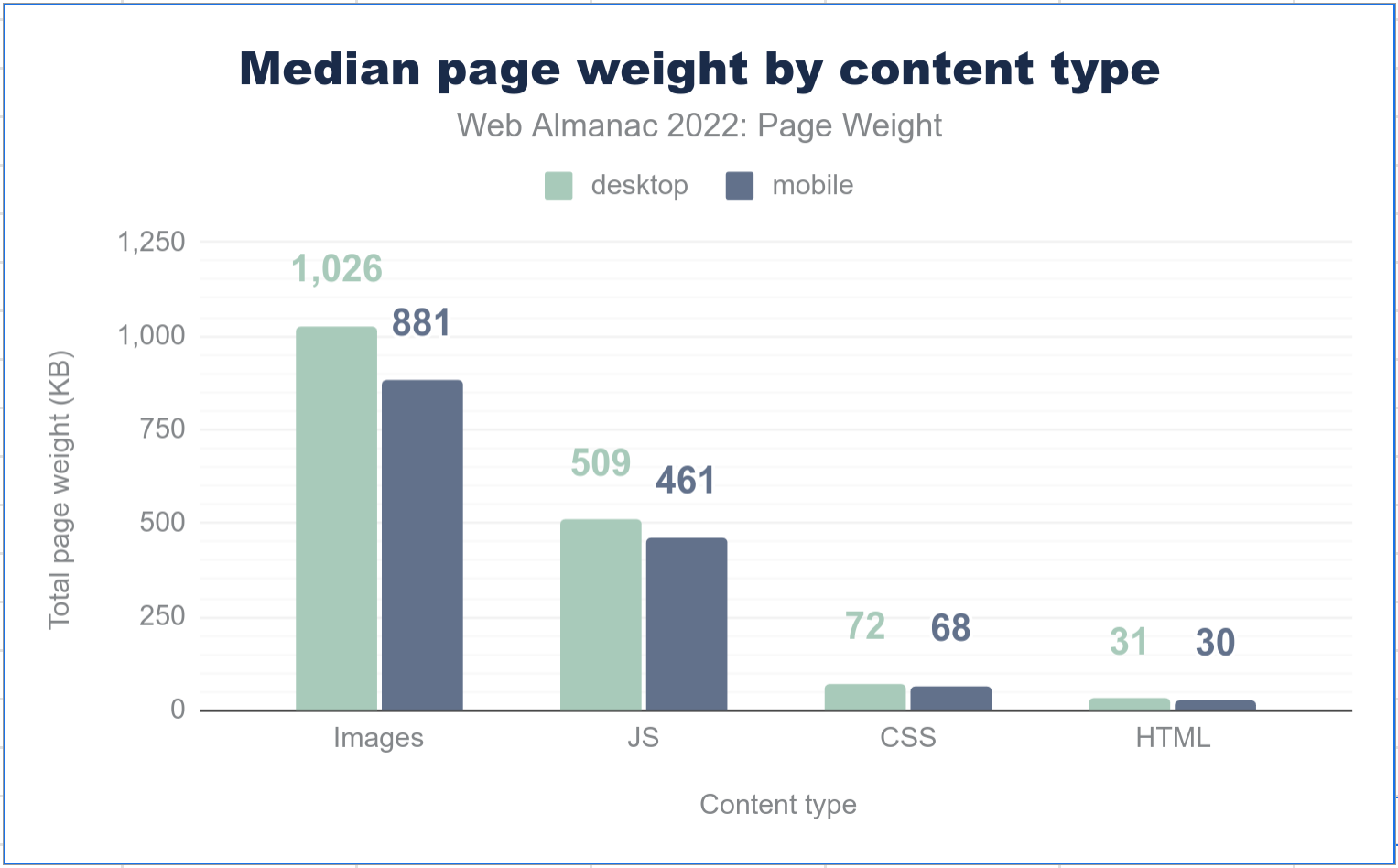
Most users only care about detecting unexpected changes, not viewing every byte of every revision. So instead of storing the full content of each resource, we store a hash of the content and compare hashes between revisions. A SHA-1 digest works fine for this and keeps storage tiny per revision.
(Storing the full content for the latest revision is still useful when you do want a real diff. Modern Page trackers in Secutils.dev keep both: a fingerprint per resource for fast change detection, plus the actual content for the latest few revisions so the Monaco-based diff viewer has something to render.)
Where this is heading
In this post we covered the obvious challenges: inline vs external resources, dynamic loading, and the storage problem. The next two posts dig into the trickier ones: handling blob: and data: resources, applying fuzzy hashing to "noisy" resources that change every page load, and hardening the scraper against malicious users.
Frequently asked questions
Why use Playwright instead of Puppeteer?
Both work. Playwright was a slightly better fit for me thanks to its multi-browser support, more polished Route/Response interception API, and the codegen tool, which Secutils.dev now uses to import recorded scenarios as tracker extractor scripts.
Why a SHA-1 hash and not SHA-256?
SHA-1 is fine for change-detection (we only need a strong probability that two byte-strings differ). It is shorter and faster to compute. Cryptographic strength is not a requirement here.
Why a separate service for the scraper?
Resource isolation, security, and independent scaling. A headless browser pointed at arbitrary URLs is a very different security profile from a typical HTTP API. Splitting it out lets us tighten sandboxing and network policy without affecting the rest of the system. See Running web scraping service securely.
Where do I see this feature today?
It is available as the Page tracker feature in Secutils.dev, alongside the related API tracker.
That wraps up today's post, thanks for taking the time to read it!
If you found this post helpful or interesting, please consider showing your support by starring secutils-dev/secutils GitHub repository. Also, feel free to follow me on Twitter, Mastodon, LinkedIn, Indie Hackers, or Dev Community.
Thank you for being a part of the community!