A primer on open-source intelligence for bug bounty hunting in Grafana

A few quick refreshers:
- The "Page Tracker" referenced below is now formally called the Page tracker (singular feature spanning content + resources + API).
- The companion sandbox repo (secutils-dev/secutils-sandbox) still hosts the
github-codeowner-file.jsextractor used in this post, you can also paste the script body directly into a new tracker or import a Playwright codegen recording for richer flows. - For credentials such as the GitHub PAT in the second half, use user secrets so the token is encrypted at rest and never appears in the tracker definition or request log.
- The original "GA announcement" admonition is preserved below as part of the historical context.
Before getting to the main topic of this blog post, I’d like to take a moment to share some exciting news (at least for me): Secutils.dev, the product for software engineers and security researchers that I’ve been working on lately, is now generally available!
Preparing the tool for GA is what has been keeping me busy for the last couple of months. I’d encourage you to quickly skim through the video guides to learn what Secutils.dev is capable of today:
- Quickly deploy and program webhooks
- Track changes in any part of a web application
- Easily generate development certificates and keys
- Slice and dice content security policies (CSP)
It’s still early days for Secutils.dev, and if you want to know what's coming, check out the roadmap.
Hello!
Today, I’d like to touch on open-source intelligence, or OSINT. According to Wikipedia, open-source intelligence is the collection and analysis of data gathered from open sources (covert sources and publicly available information) to produce actionable intelligence. As you can infer from the definition, OSINT is a vast topic, and the best way to understand such broad topics is through concrete, narrow-scoped practical examples. In this blog post, I’d like to share one of the approaches on how OSINT techniques can be applied to bug bounty hunting for products with publicly hosted code on GitHub, using the awesome open-source project Grafana as an example. Read on!
I’m not a security researcher nor a bug bounty hunter myself, but as an application security engineer, I think about these essential participants of the security ecosystem and how they might approach the applications I defend day and night. Therefore, I have some insights to share. Everything in this post is for educational purposes only and is solely targeted at well-intentioned researchers and bug bounty hunters who follow responsible and ethical security issue disclosure rules.
Keep your focus narrow
As a security researcher, there are many ways you can approach an application you want to explore for potential security flaws, from trying to use it in esoteric conditions with tricky input data to thoroughly learning every bit and piece of its source code, hoping to find anything that can knock it out. A seasoned researcher knows that these approaches, unfortunately, can be very time-consuming with a bleak chance of success. The first step is usually to reduce the scope of research to improve the ratio between time spent and the chance of a successful finding.
If it’s a new project for you, I’d recommend concentrating on understanding the security model used in the application: authentication, authorization, and integration with third-party applications and services. In an ideal scenario, you might find a very rewarding flaw in the security model itself, and in the worst case, you’ll have a better chance to spot when security primitives are used incorrectly in other areas of the application.
On one hand, in a large and complex application like Grafana, the security model is complex to grasp. On the other hand, it’s just as complex for the application developers. To manage this complexity, the application is frequently split into separate well-defined domains with clear owners. If you know these domains and/or owners, you know where to look. GitHub, or the GitHub CODEOWNERS file specifically, is your ally here.
GitHub CODEOWNERS file
Let’s take a look at the excerpt from the CODEOWNERS file for the grafana/grafana repository:
…
/.changelog-archive @grafana/grafana-release-guild
/CHANGELOG.md @grafana/grafana-release-guild
/CODE_OF_CONDUCT.md @grafana/grafana-community-support
…
/.github/workflows/update-make-docs.yml @grafana/docs-tooling
/.github/workflows/snyk.yml @grafana/security-team ----> (1) <----
…
# Cloud middleware
/grafana-mixin/ @grafana/grafana-backend-services-squad
# Grafana authentication and authorization ----> (2) <----
/pkg/login/ @grafana/identity-access-team
/pkg/services/accesscontrol/ @grafana/identity-access-team
/pkg/services/anonymous/ @grafana/identity-access-team
…
The CODEOWNERS file format is pretty self-describing - every line contains a path in the source code repository and the corresponding owner, either a specific person or an entire team. (1) and (2) are what should have caught your eye - it’s easy to spot at least two security-oriented teams in the file - @grafana/security-team and @grafana/identity-access-team. Great, now we can discern and learn more about the security-related domains these teams own.
Let’s assume you have a slightly better understanding of Grafana’s security model domains now, but what’s next? You might also say that generally security-related code is the one that’s hardest to break, and I’d agree. But there is one exception - newly written code! Pressing deadlines to deliver a new feature that force engineers to speed up the review process, code written by engineers who are new to the security domain, incomplete security fixes, and so on and so forth - these are some of the many reasons why newly written code is so compelling for our purpose. That’s the weakest point you might want to target, and there are two potential vectors here: completely new security domains, e.g., a new SSO integration, or changes in the existing domains, e.g., a bug fix.
Automating change tracking
Of course, you can periodically manually scan the CODEOWNERS file for newly introduced domains or write a dedicated tool for that, but it’s a very laborious task that makes the approach somewhat unsustainable in the long term, especially if you have multiple applications to work with and multiple angles to look at. That’s where tools like Secutils.dev can be helpful! Let me show you how you can use the “Page Tracker” utility to watch the content of the CODEOWNERS file on a specific schedule. I won’t be covering what this utility is for and how to use it. You can spend a couple of minutes and watch a video guide. I’ll just provide tracker settings you can use for your tracker:
| Name | |
| URL | |
| Revisions | |
| Frequency | |
| Content extractor | |
The important part here is the Content extractor script that is injected into a target page. All this script does is load another external module from the secutils-dev/secutils-sandbox repository and run its run function. The run function expects the GitHub repository owner (grafana), repository name (grafana), and the teams to look for in a CODEOWNERS file. I could put all the logic inside the content extractor script itself, but I prefer to keep the main logic in a separate file to make it easier to debug and iterate on it. Let’s take a look at what I have in the github-codeowner-file.js script (the full source code can be found here):
import type { WebPageContext } from './types';
export async function run(
context: WebPageContext,
owner: string,
repo: string,
teams: string[],
): Promise<string> {
const codeOwnersUrl = `https://raw.githubusercontent.com/${owner}/${repo}/main/.github/CODEOWNERS`;
const lines = (await fetch(codeOwnersUrl).then((response) => response.text())).split('\n') ?? [];
const rows: Array<Array<string | null | undefined>> = [['Owners', 'Path']];
for (const line of lines) {
const [path, owners] = line.split(' ').sort();
if (owners && teams.some((team) => owners.includes(team))) {
rows.push([owners, path]);
}
}
const module = await import('markdown-table');
return module.markdownTable(rows, { align: ['l', 'c'] });
}
The script simply loads the CODEOWNERS file from the specified repository, parses it, and only retains entries that are owned by the specified teams. The result is returned as a nice markdown table. Here’s how the result looks like in Secutils.dev:
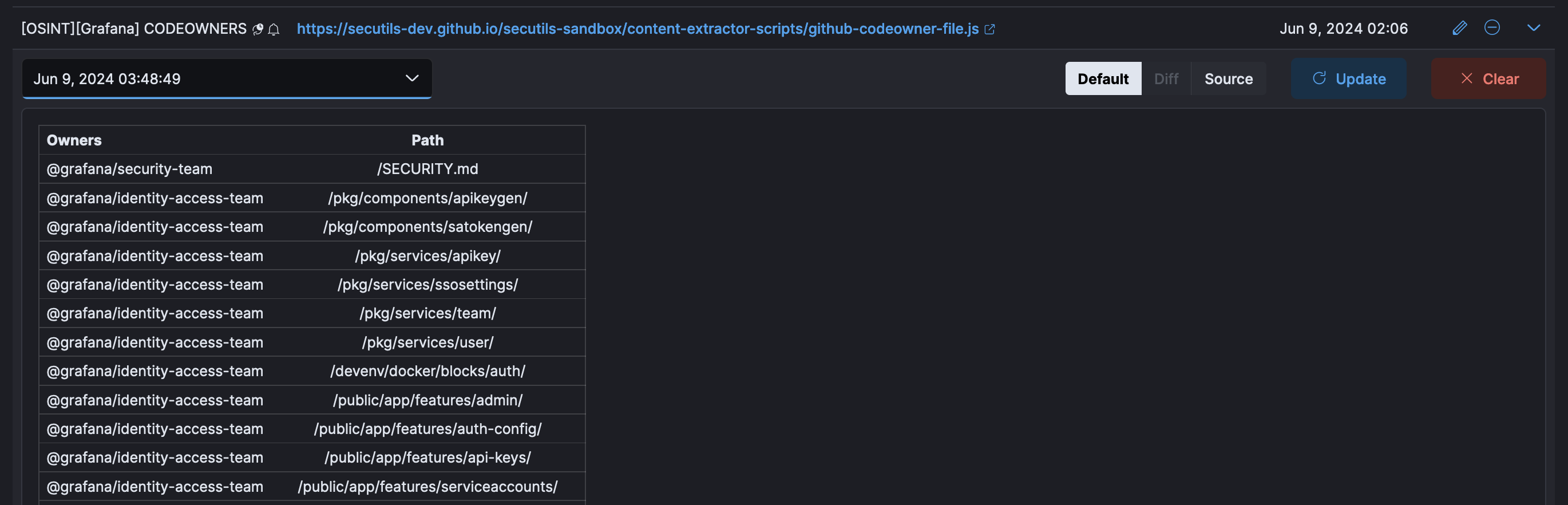
So what we have now is a regular job that runs daily, parses the content of the CODEOWNERS file for the specified repository, extracts the areas that are owned by the specified GitHub teams, and notifies you via email if it detects any changes. Now, as soon as a new security domain is introduced, you can go and take a closer look at it right away, no need to waste time on doing it manually on a regular interval. Nice!
Okay, but new domains aren’t introduced that often. What about changes in the existing domains? We can do that too. Let’s tweak our content extractor scripts. The easiest way to know if there were any changes in a specific security domain is to take a look at the recent commits for the specified path. To do that, we can use GitHub’s Get commits API. For public repositories, this API can be used anonymously, but it has a very low request rate limit - just 60 requests per hour, so it’s better to create a GitHub personal access token (PAT) to query this API. Let’s tweak our main content extractor script to provide an access token:
const apiToken = 'github_pat_11xxxxxxxx'; // GitHub personal access token
const teams = [
'@grafana/security-team',
'@grafana/identity-access-team'
];
return import('https://secutils-dev.github.io/secutils-sandbox/content-extractor-scripts/github-codeowner-file.js')
.then((module) => module.run(context, 'grafana', 'grafana', teams, apiToken));
And here are the changes we need to make in the dynamically loaded script:
import type { Endpoints } from '@octokit/types';
import type { WebPageContext } from './types';
export async function run(
context: WebPageContext,
owner: string,
repo: string,
teams: string[],
apiToken?: string,
): Promise<string> {
const codeOwnersUrl = `https://raw.githubusercontent.com/${owner}/${repo}/main/.github/CODEOWNERS`;
const lines = (await fetch(codeOwnersUrl).then((response) => response.text())).split('\n') ?? [];
// Use API token if provided to have higher request rate limit.
// https://docs.github.com/en/rest/using-the-rest-api/rate-limits-for-the-rest-api?apiVersion=2022-11-28.
const headers: Record<string, string> = apiToken
? { Authorization: `Bearer ${apiToken}`, 'X-GitHub-Api-Version': '2022-11-28' }
: { 'X-GitHub-Api-Version': '2022-11-28' };
// Retrieve the latest commit for the specified path.
const getCommitLink = async (path: string) => {
try {
const commits = (await fetch(
`https://api.github.com/repos/${owner}/${repo}/commits?path=${encodeURIComponent(path)}&per_page=1`,
{ headers },
).then((response) => response.json())) as Endpoints['GET /repos/{owner}/{repo}/commits']['response']['data'];
if (commits.length === 0) {
return 'N/A (no commits found)';
}
const topCommit = commits[0];
const commitLabel =
topCommit.commit.author?.name && topCommit.commit.author?.date
? `${topCommit.commit.author.name} on ${topCommit.commit.author.date}`
: topCommit.sha.slice(6);
return `[${commitLabel}](${topCommit.html_url})`;
} catch (err) {
return `N/A (${(err as Error).message ?? 'unknown error'})`;
}
};
const rows: Array<Array<string | null | undefined>> = [['Owners', 'Path', 'Last commit']];
for (const line of lines) {
const [path, owners] = line.split(' ').sort();
if (owners && teams.some((team) => owners.includes(team))) {
rows.push([owners, path, await getCommitLink(path)]);
}
}
const module = await import('markdown-table');
return module.markdownTable(rows, { align: ['l', 'c'] });
}
The change here is that we are now adding a third column to our markdown table, which we fill with the latest commit information returned from the getCommitLink function invoked with the path extracted from the CODEOWNERS file. Easy! Here’s how the result looks:
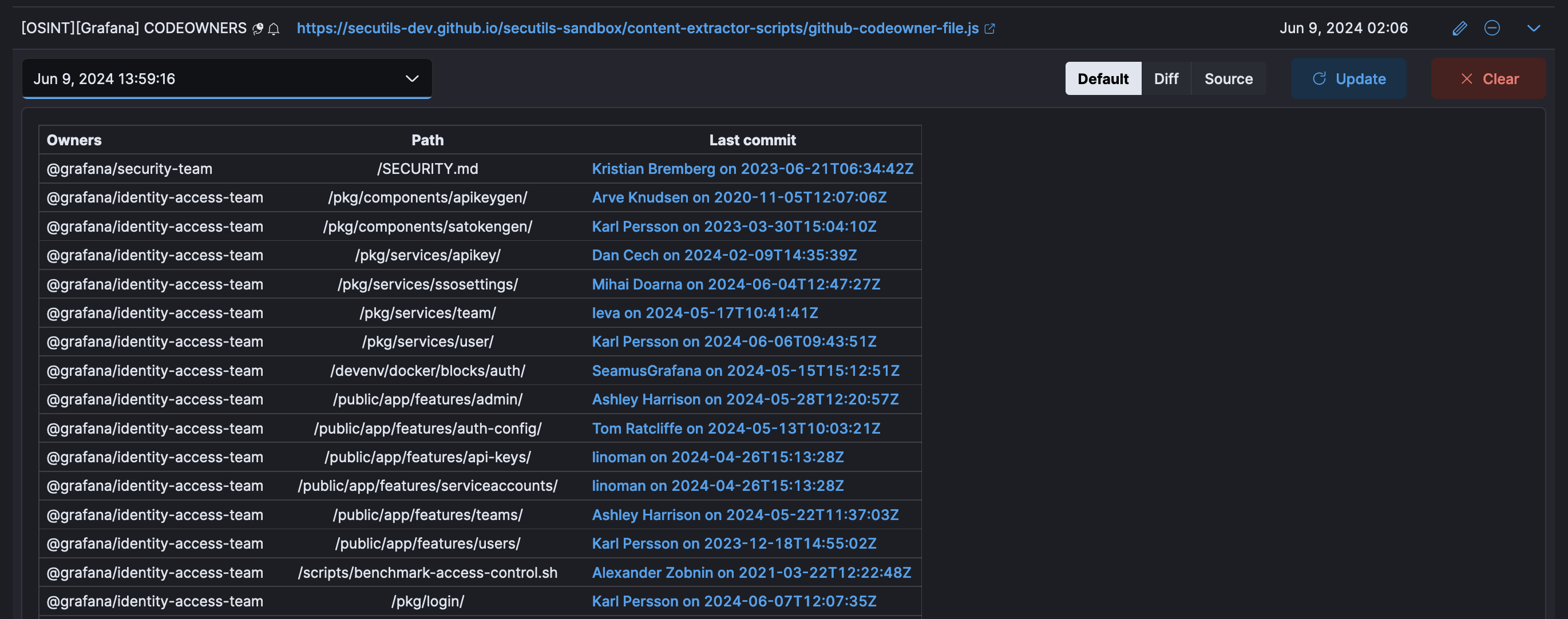
Now, when a new commit is detected in any security domain, you’ll get an email notification. Then, you can go to Secutils.dev to see what has changed exactly with the Diff feature and click on the commit link to learn more about the specific changes. Great, isn’t it?
But wait, there's more
Tracking changes in the CODEOWNERS file and security-related domains is just the tip of the open-source intelligence iceberg. If you want to fully embrace its principles, you can go a few steps further since the commit authors can give you a better idea about the composition of the security teams in a particular organization, which isn’t publicly available information. What can you do with this new data? Well, quite a lot.
For example, the majority of security issues are found outside the security domains, so it’s hard to recognize security fixes automatically. But there is a high chance that some members of the security teams can be tagged for review or advice on the pull requests with those fixes. So you might want to take a closer look at the pull requests for the domains unrelated to security if security folks are involved in one way or another, assuming you know who these security folks are 😬.
The fun part of open-source intelligence is that it doesn’t limit you to information sources as long as they are public. Social networks, such as LinkedIn, are invaluable sources of information for security researchers, and sadly for bad actors as well.
If you know who the security team members are, you can go a little bit crazy and set up a dedicated tracker for their LinkedIn profiles. When you detect this infamous “I’m happy to announce” message on their profile, go and check that their access was properly revoked, name-bound sub-domain names and S3 buckets are still owned by the organization, and Slack, Zoom, and GitHub profile handles are properly secured. Security team members usually have elevated privileges within organizations, and when they depart, special care should be taken. If you notice it’s not the case, please disclose it responsibly and ethically!
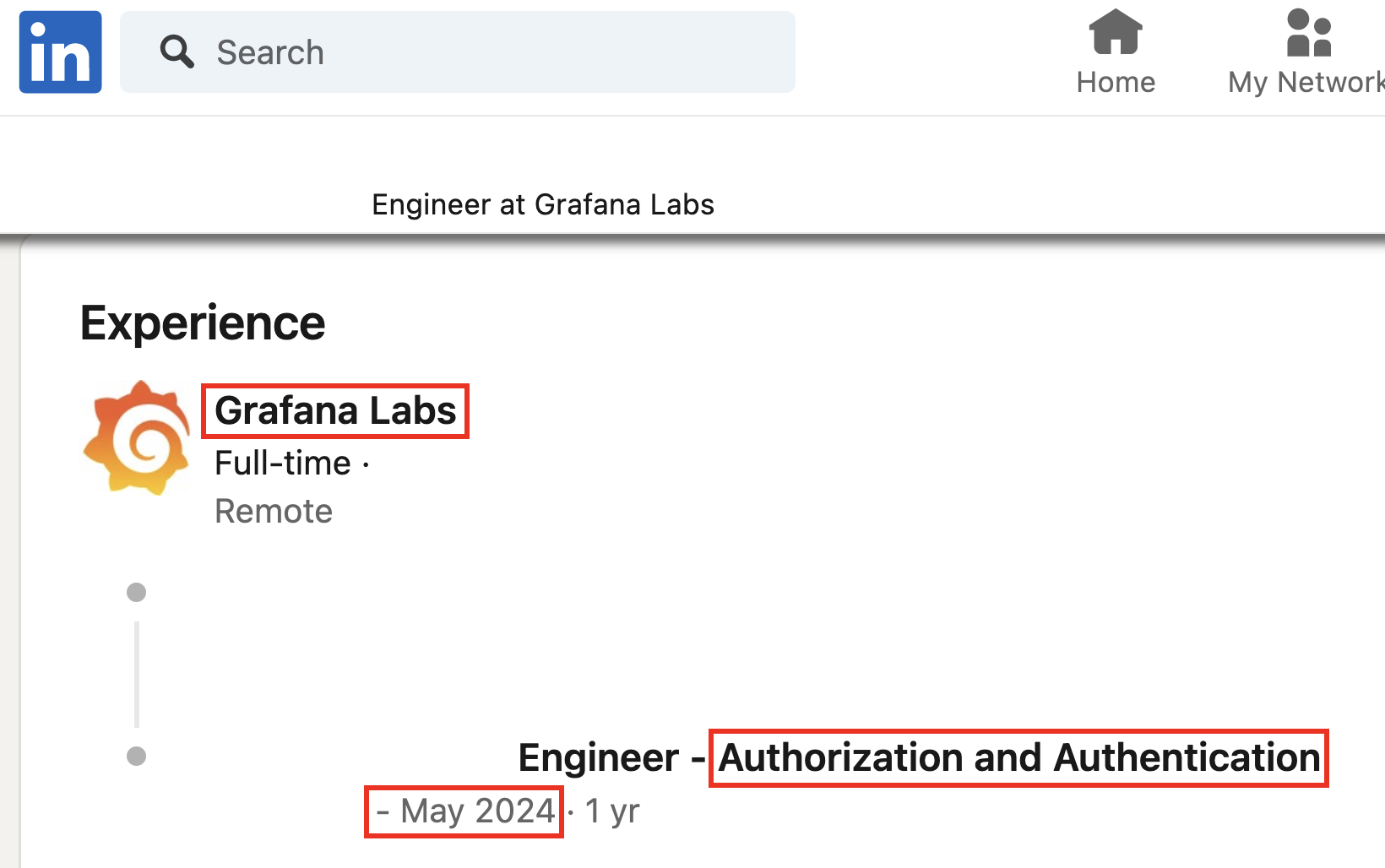
I know it might look a lot like stalking, but it’s not. It’s about understanding the security posture of the organization you’re interested in, and it’s a very important part of the security research process. If you’re not comfortable with this, you can always stick to the technical part of the research, which is also very rewarding.
In this blog post, I’ve covered just the most basic and obvious ways to apply open-source intelligence for security research, but there are many more. State-backed actors are known to use these techniques combined with other techniques such as social engineering, and it’s important to understand how they work to be able to defend against them. Let me know if it’s something you’d like to learn more about!
Frequently asked questions
Where do I store the GitHub PAT used in the second tracker?
In a user secret. Secrets are encrypted at rest, never appear in the tracker definition or the request log, and can be referenced from any extractor script by name.
Can I do this for any other GitHub repository?
Yes. Substitute the owner and repo arguments in the extractor invocation. The same pattern works for any project that uses a CODEOWNERS file, GitLab CODEOWNERS, or even an internal OWNERS convention as long as the file is reachable over HTTPS.
How often should the tracker run?
For a fast-moving project like Grafana, daily is a reasonable cadence. For slower-moving projects, weekly is plenty. Page trackers support arbitrary cron expressions if you want to be more specific (e.g. weekday-only mornings).
What's the right way to use this responsibly?
Stick to the responsible disclosure playbook. The techniques described here are equally useful to defenders watching their own org's posture, which is just as legitimate a use case.
That wraps up today's post, thanks for taking the time to read it!
If you found this post helpful or interesting, please consider showing your support by starring secutils-dev/secutils GitHub repository. Also, feel free to follow me on Twitter, Mastodon, LinkedIn, Indie Hackers, or Dev Community.