Building a scheduler for a Rust application

Hello!
As you might have learned from the Q3 2023 iteration plan, one focus of that quarter was adding automatic, scheduled resource checks to the Web Scraping → Page tracker feature in Secutils.dev. This post covers how I designed the scheduler that powers it. If you are building something similar in Rust, hopefully a few details here are useful.
The scheduler described here was the right starting point, but its scope and shape have changed significantly since this post:
- Database: jobs are now persisted in PostgreSQL (Secutils.dev migrated off SQLite in
1.0.0-beta.1, May 2024). The custom SQLite job store referenced below is no longer used. - Trackers: scheduling for Page trackers and API trackers is now handled by the standalone Retrack service (a git submodule at
components/retrack). Retrack also added arbitrarycrontabexpressions, debug runs, screenshots, the Camoufox stealth engine, and tracker execution logs. - Notifications: still scheduled by an in-process Tokio cron job inside the API server, with the same
tokio-cron-schedulercrate.
So the in-process scheduler still exists for the things tightly coupled to the Secutils.dev API (notifications, periodic housekeeping). Tracker scheduling specifically lives in Retrack now.
What the scheduler needs to do
The scheduler underpins a lot of Secutils.dev behaviour. It runs periodic resource and content checks for trackers, dispatches notifications, and handles other recurring background work. So it needs to be performant, flexible, and reliable.
Performance: keep it in-process
For lowest possible overhead I wanted to avoid an external scheduler (e.g. Kubernetes CronJob) and run scheduling inside the Rust API server itself. That has the bonus of making on-prem self-hosting trivial: a single binary brings the API and its background work, no extra infrastructure needed. In the Rust ecosystem, the obvious choice for this is Tokio, the async runtime everything else builds on.
If you need true cron-style scheduling at the cluster level (e.g. a job that should run even if the API is down), Kubernetes CronJob or a dedicated job runner is still the right answer. For "the API is up so the schedule can run too" workloads, in-process is cheaper and simpler.
Flexibility: cron syntax
The scheduler has to support both one-shot jobs and repeating jobs with arbitrary cadence. For user-facing trackers, "hourly" or "daily" was a fine starting point, but I wanted a path to giving users full control: 0 0 * * 6 ("midnight every Saturday"), and so on. Crontab syntax is the obvious vocabulary here: well-understood, dense, and very expressive (custom cron schedules for trackers eventually shipped in 1.0.0-beta.2).
Reliability: persistent job state
Secutils.dev pushes new versions regularly, and pods get rescheduled, restarted, or replaced. The scheduler must not lose its job state when the process restarts, jobs should resume from where they were as soon as the API comes back up. That requires persistent storage. Originally that meant SQLite, today it's PostgreSQL.
The crate I picked
After a few hours of research I landed on tokio-cron-scheduler:
- Performance: Tokio under the hood.
- Flexibility: one-shot and repeating jobs, full crontab syntax.
- Reliability: pluggable persistent storage. Out of the box it supports PostgreSQL and NATS; SQLite required implementing the storage trait myself.
- Maintainability: open-source, permissively licensed, simple architecture.
A couple of architecture diagrams from the project repo to give a sense of how it works:
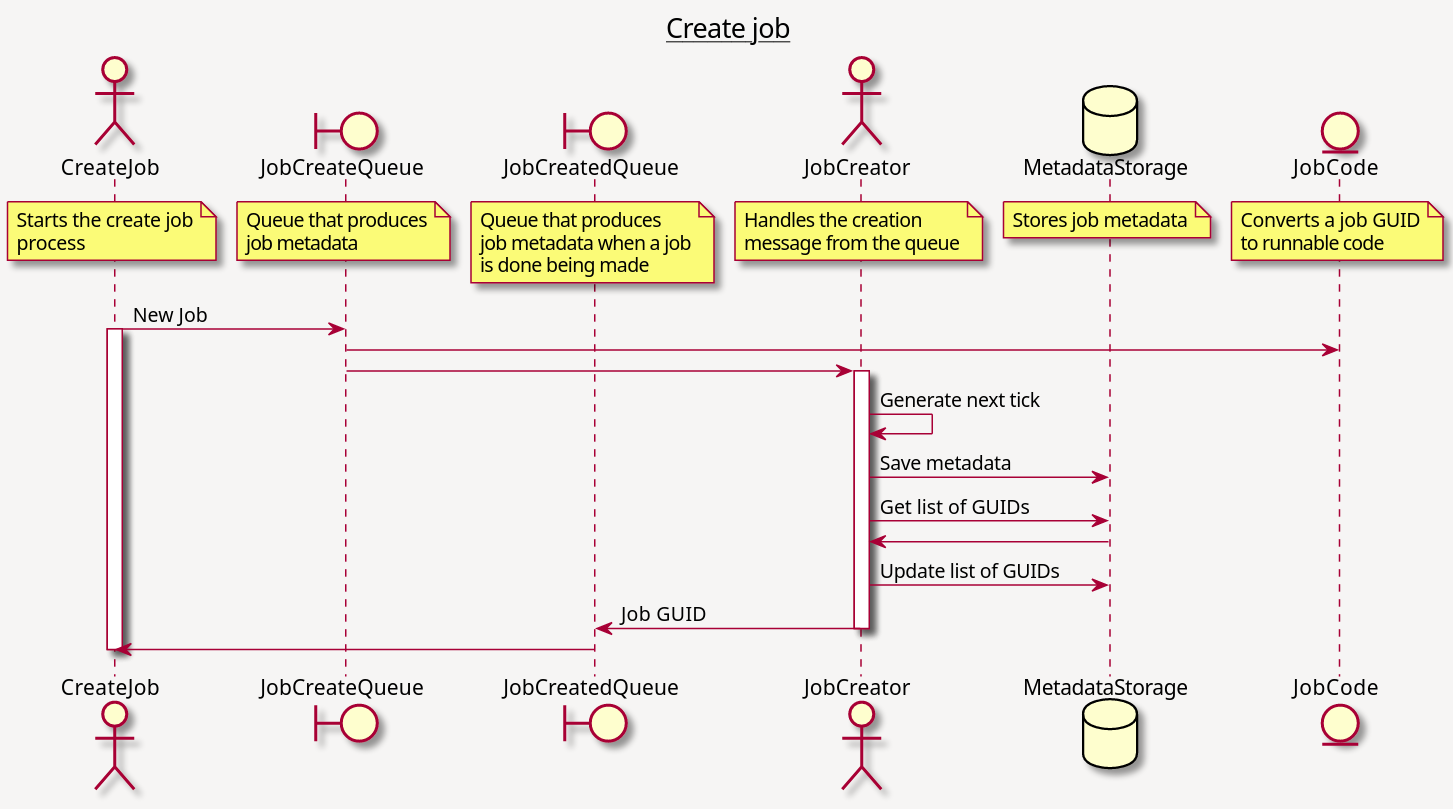
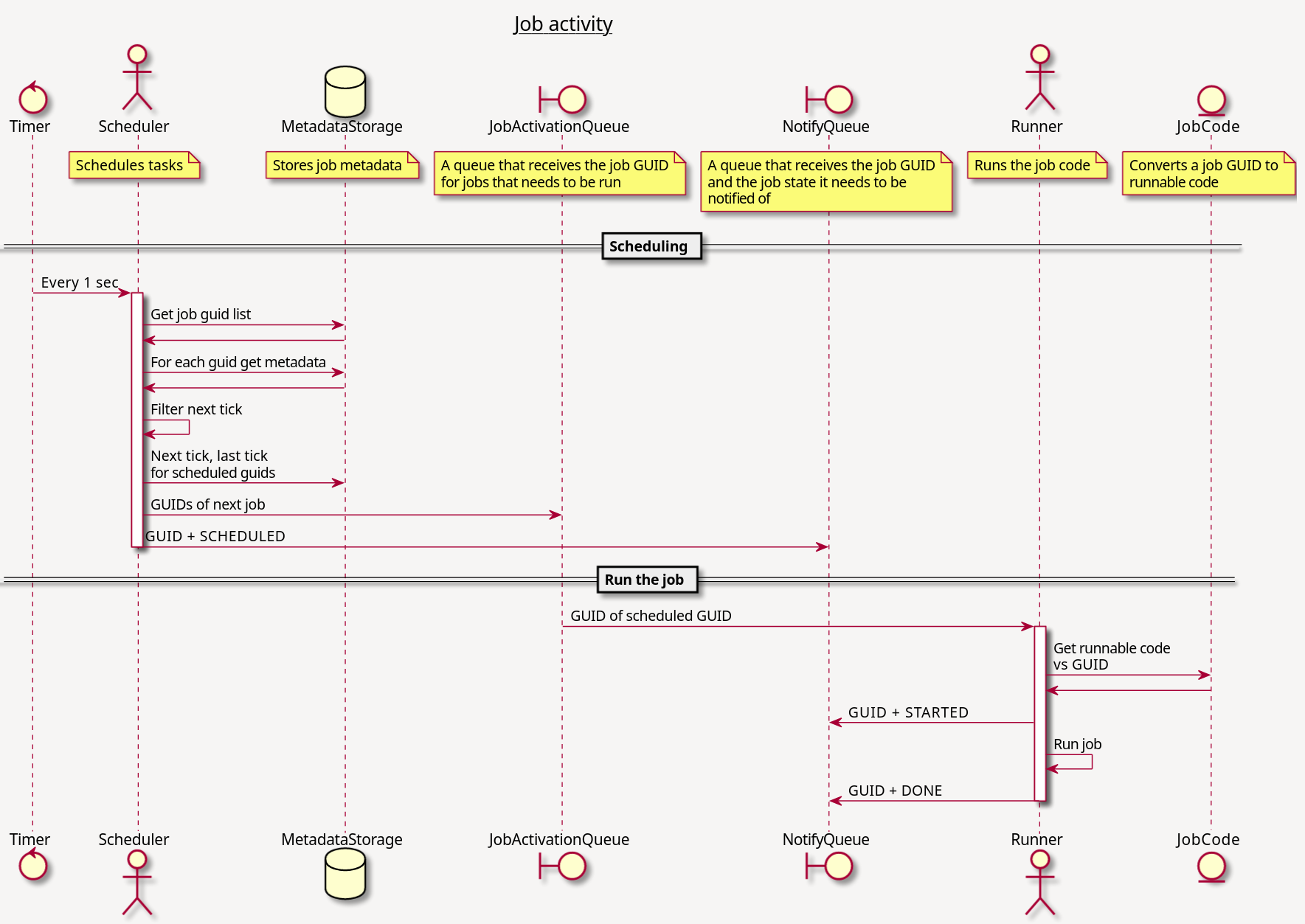
When this post was originally written I had just finished a custom SQLite storage backend. After the migration to PostgreSQL the custom backend was retired in favour of the upstream Postgres backend.
What lives where today
The scheduler story has split in two:
- In-process scheduler (still
tokio-cron-scheduler, still inside the API server): notifications batching, periodic housekeeping, anything that's tightly coupled to the API's data model and lifecycle. Source lives undersrc/scheduler/. - Retrack scheduler (a separate Rust service): everything related to tracker execution. Retrack also owns the integration with the Web Scraper, the diff/revision storage, retries with backoff, and the execution log. See the Retrack repository for details.
Splitting tracker scheduling out into Retrack has paid off in two ways:
- Independent scaling. Tracker workloads are bursty and CPU/network-heavy compared to the API. Running them in their own process means they cannot starve the API of resources.
- Reuse. Retrack is now used by other projects beyond Secutils.dev, which keeps the scheduling/scraping abstractions honest.
Frequently asked questions
Why an in-process scheduler instead of Kubernetes cron jobs?
Easier on-prem self-hosting (a single binary instead of "a binary plus a Kubernetes operator"), lower latency for small jobs, and simpler local development. Kubernetes CronJob is still the right answer if you need cluster-scale scheduling that survives the API being down.
Why migrate the job store from SQLite to PostgreSQL?
Concurrent writers. Once the scheduler started fanning out to many concurrent tracker checks, SQLite's single-writer model became a real bottleneck. PostgreSQL also gives us proper indexing, JSONB columns for job payloads, and standard backup tooling.
Why use a third-party crate instead of writing it myself?
tokio-cron-scheduler covers the boring bits (cron parsing, tick loop, persistence trait, missed-job handling) so I could focus on Secutils.dev-specific behaviour. The crate is small enough that I can patch or fork if needed without inheriting much risk.
Where does Retrack come in?
Retrack is the standalone open-source project that handles tracker scheduling and headless-browser execution for Secutils.dev. It started life as code inside the Secutils.dev repo, then graduated to its own repository so other projects could reuse it. Repo: secutils-dev/retrack.
That wraps up today's post, thanks for taking the time to read it!
If you found this post helpful or interesting, please consider showing your support by starring secutils-dev/secutils GitHub repository. Also, feel free to follow me on Twitter, Mastodon, LinkedIn, Indie Hackers, or Dev Community.
Thank you for being a part of the community!