What is a page tracker?
A page tracker is a utility that empowers developers to detect and monitor the content of any web page. Use cases range from ensuring that the deployed web application loads only the intended content throughout its lifecycle to tracking changes in arbitrary web content when the application lacks native tracking capabilities. In the event of a change, whether it's caused by a broken deployment or a legitimate content modification, the tracker promptly notifies the user.
Currently, Secutils.dev doesn't support tracking content for web pages protected by application firewalls (WAF) or any form of CAPTCHA. If you require tracking content for such pages, please comment on #secutils/34 to discuss your use case.
On this page, you can find guides on creating and using page trackers.
The Content extractor script is essentially a Playwright scenario that allows you to extract almost anything from the web page as long as it doesn't exceed 1MB in size. For instance, you can include text, links, images, or even JSON.
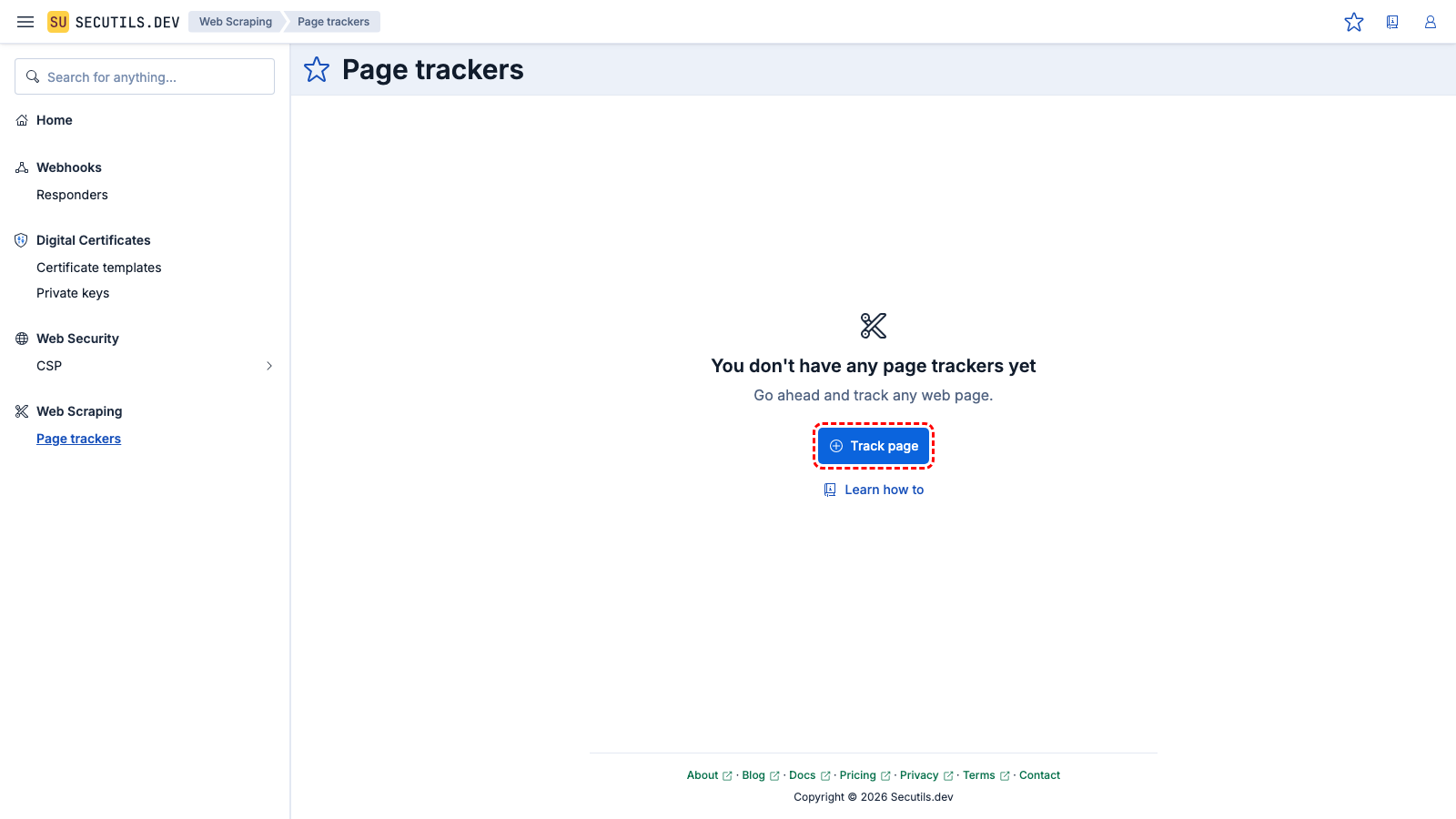
Create a page tracker
In this guide, you'll create a simple page tracker for the top post on Hacker News:
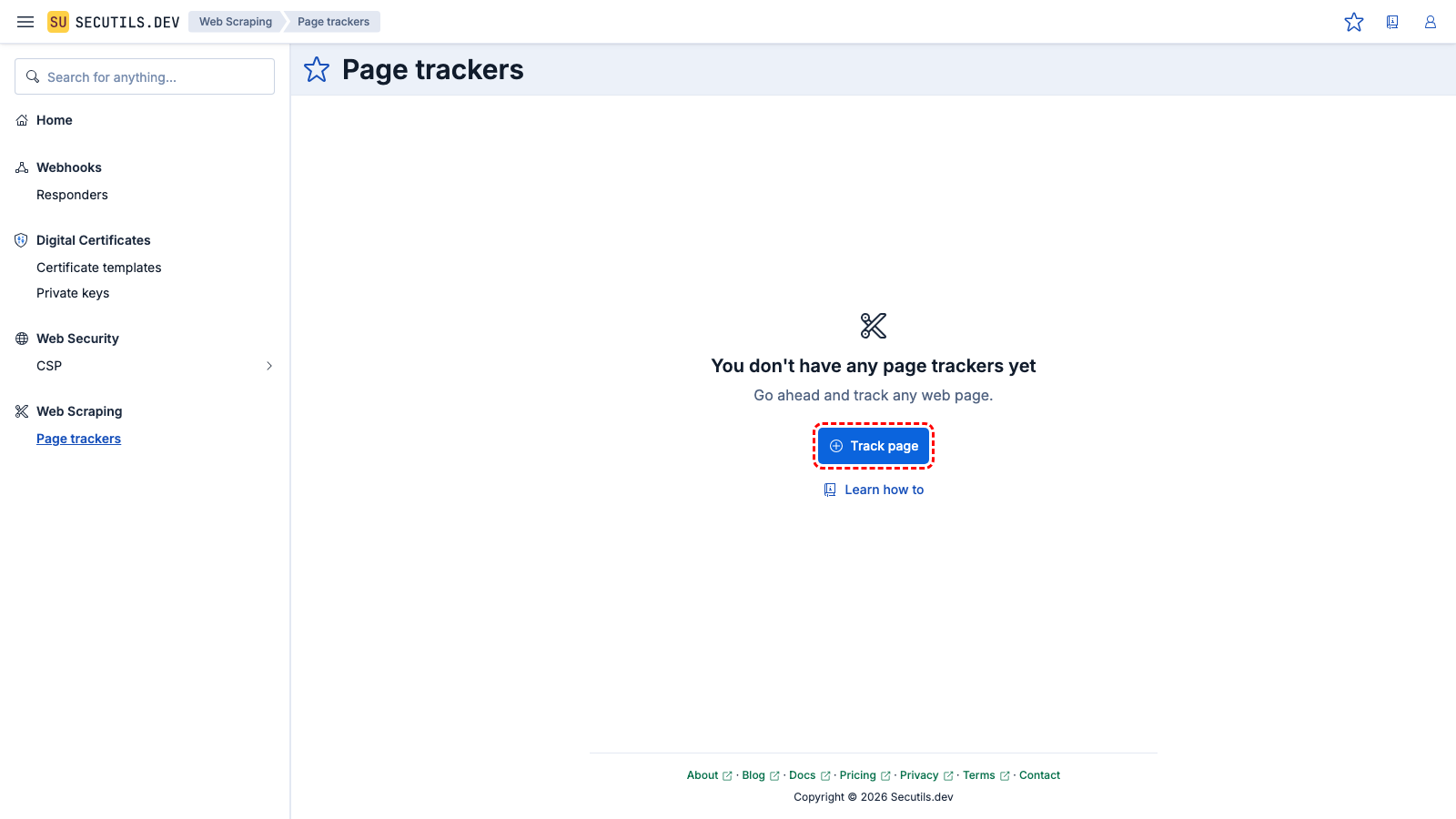
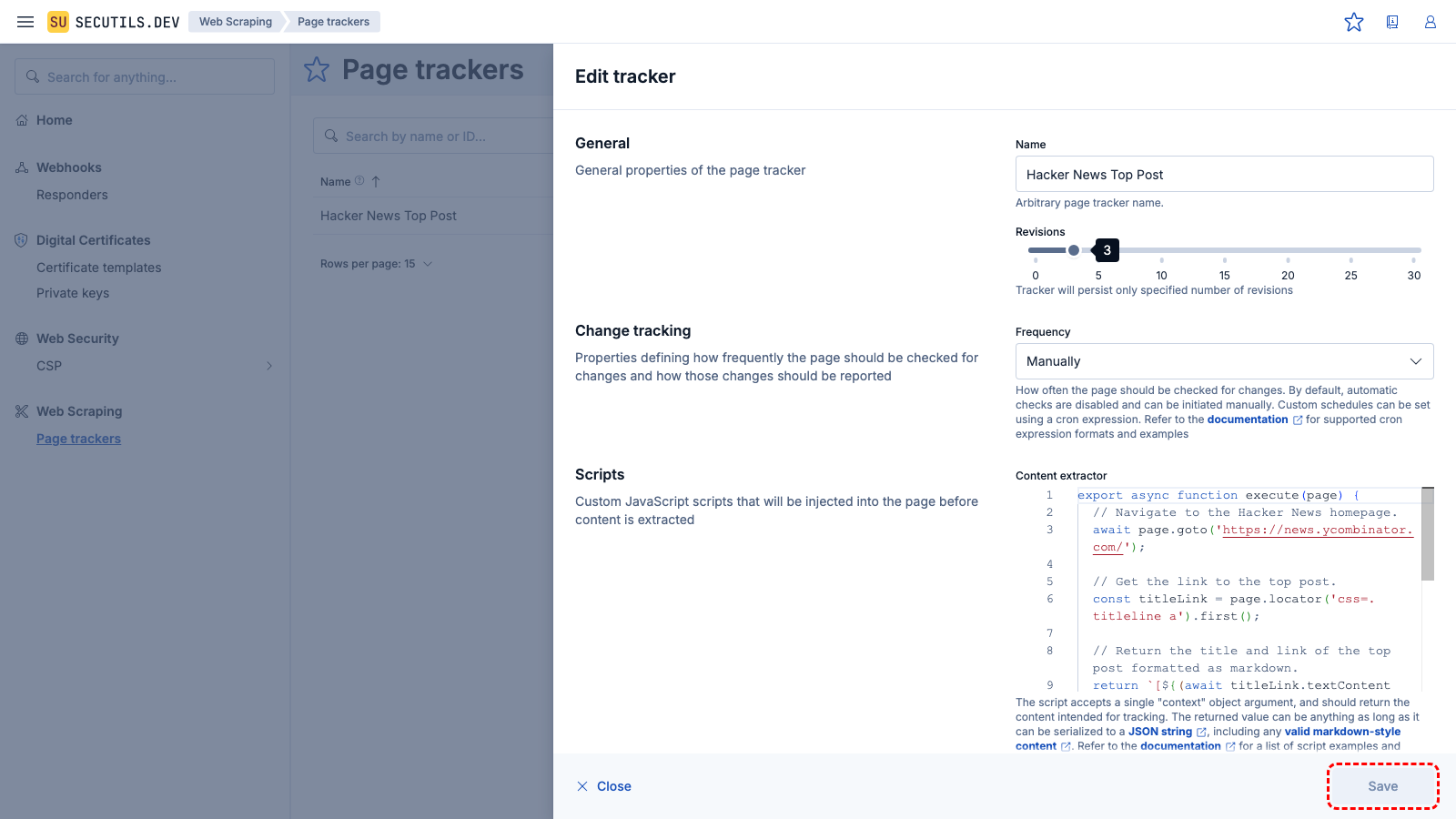
| Name | |
| Content extractor | |
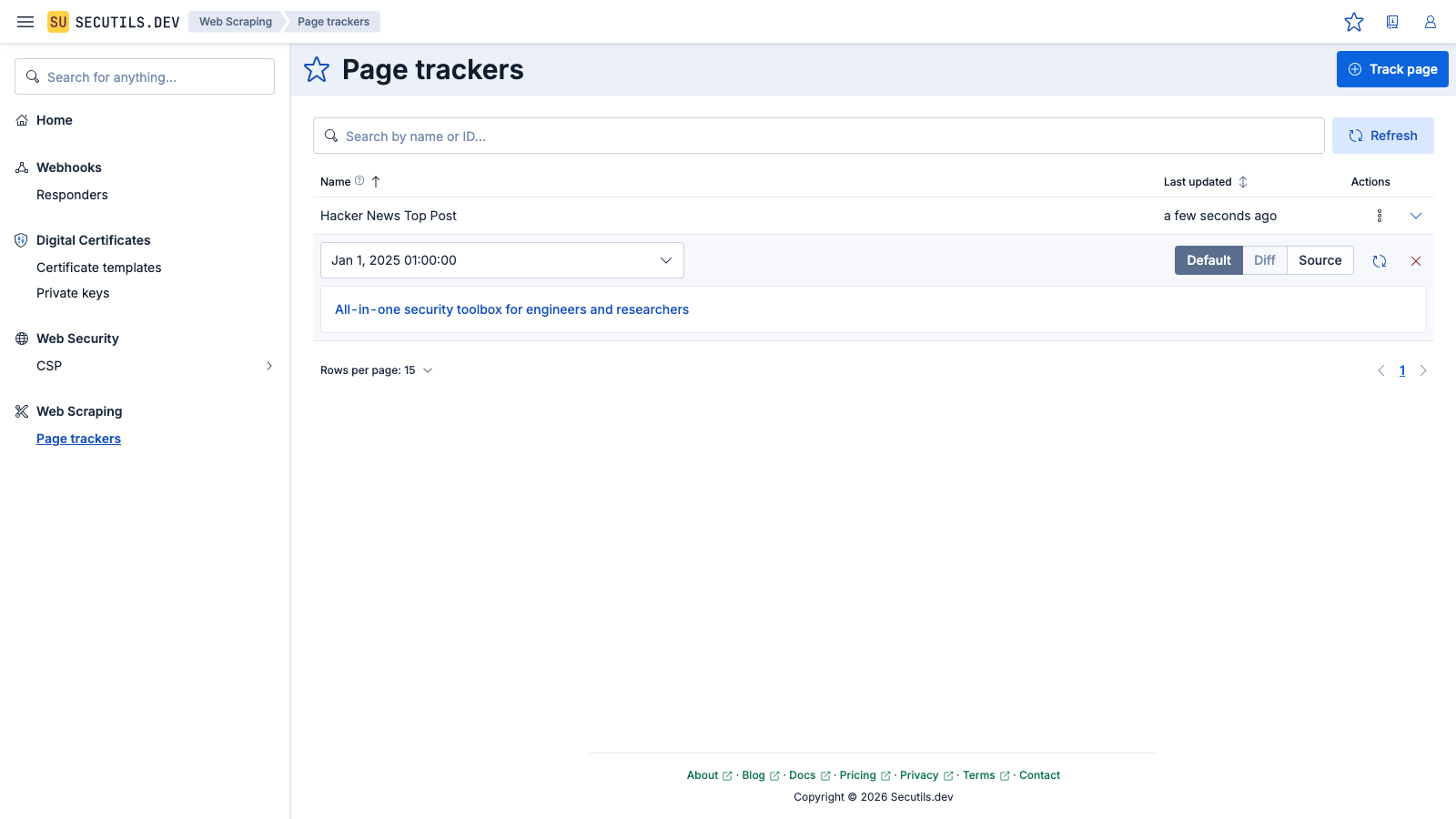
The content includes only the title of the post. However, as noted at the beginning of this guide, the content extractor script allows you to return almost anything, even the entire HTML of the post.
Detect changes with a page tracker
In this guide, you'll create a page tracker and test it with changing content:
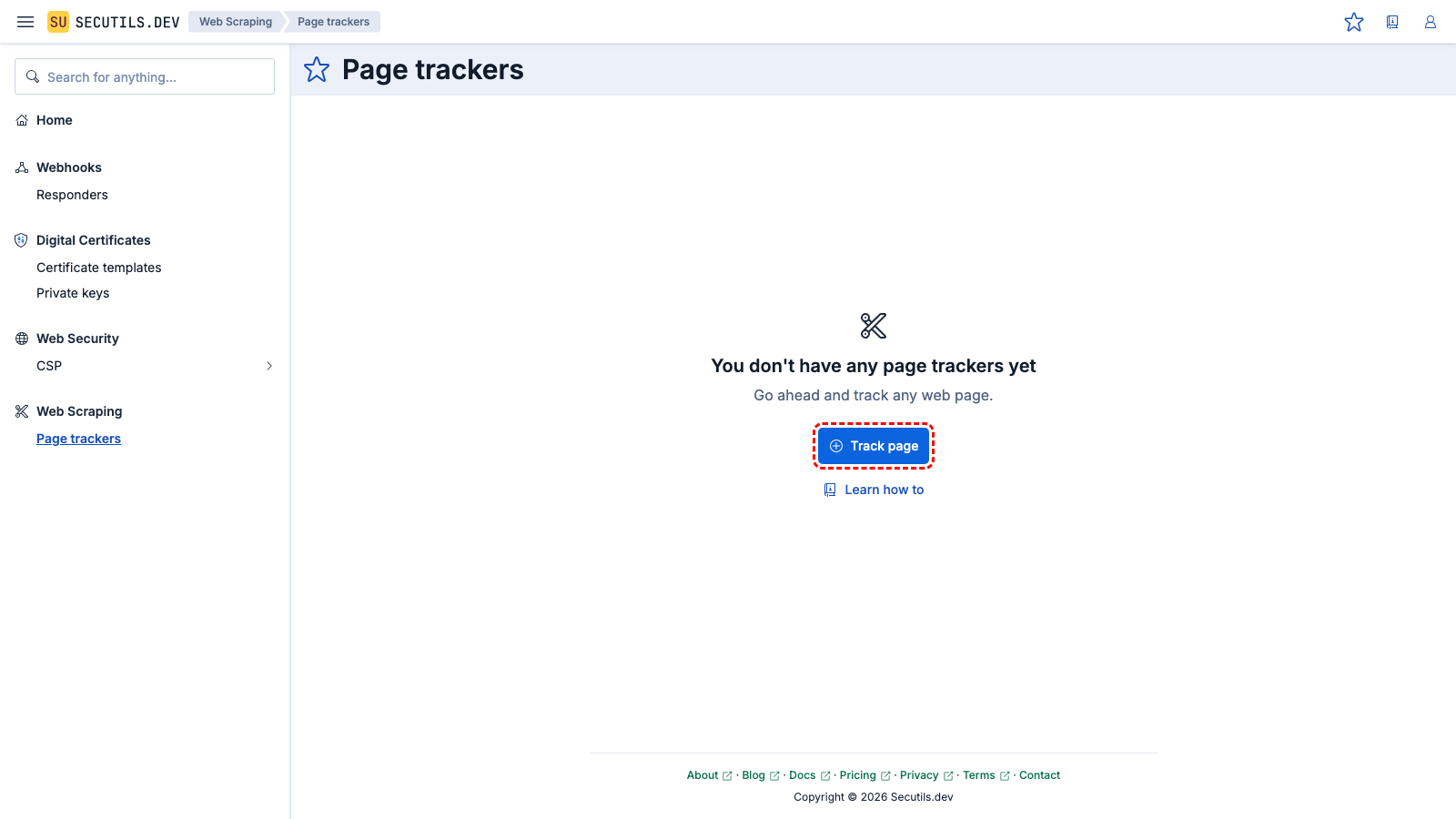
| Name | |
| Content extractor | |
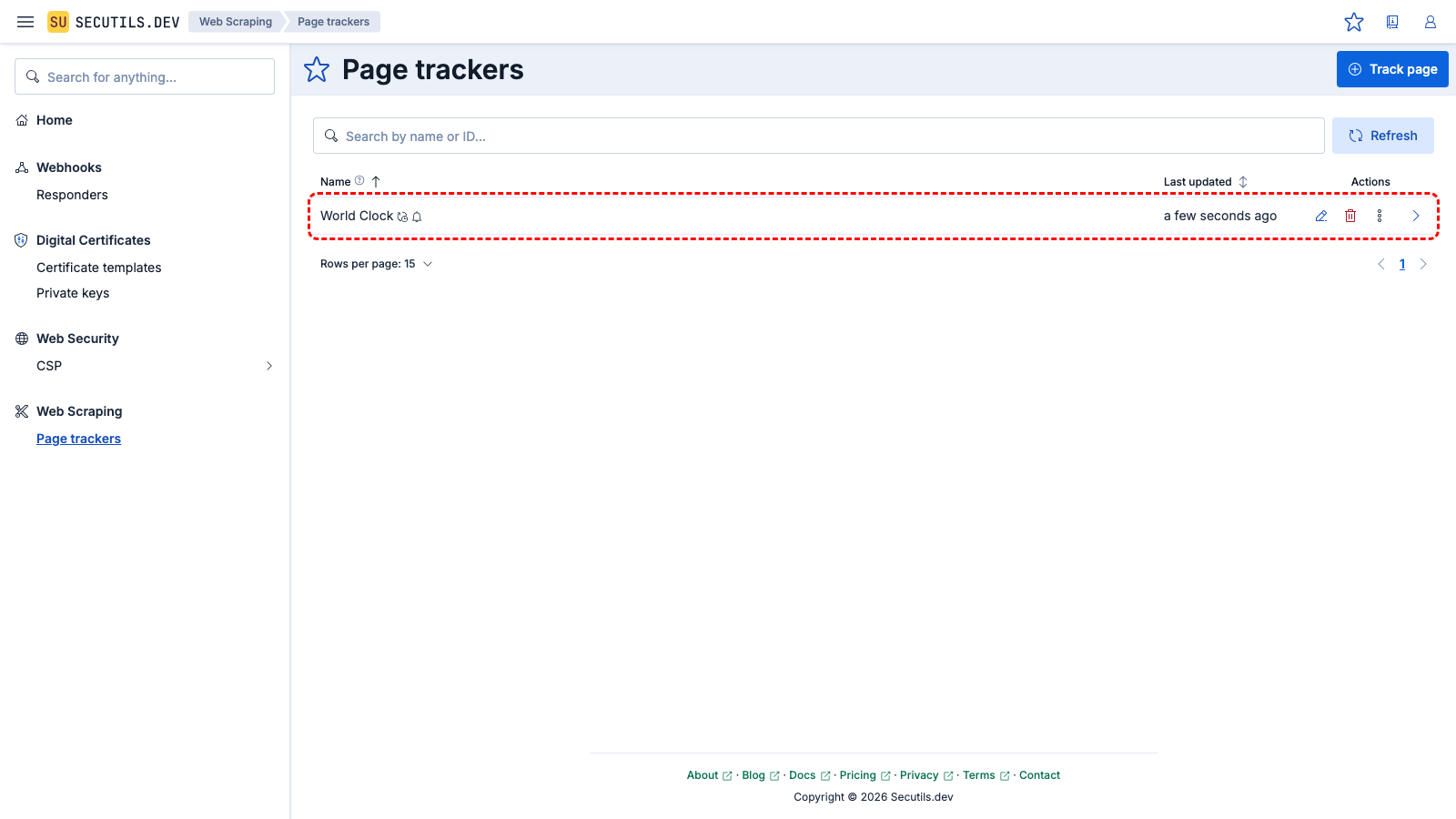
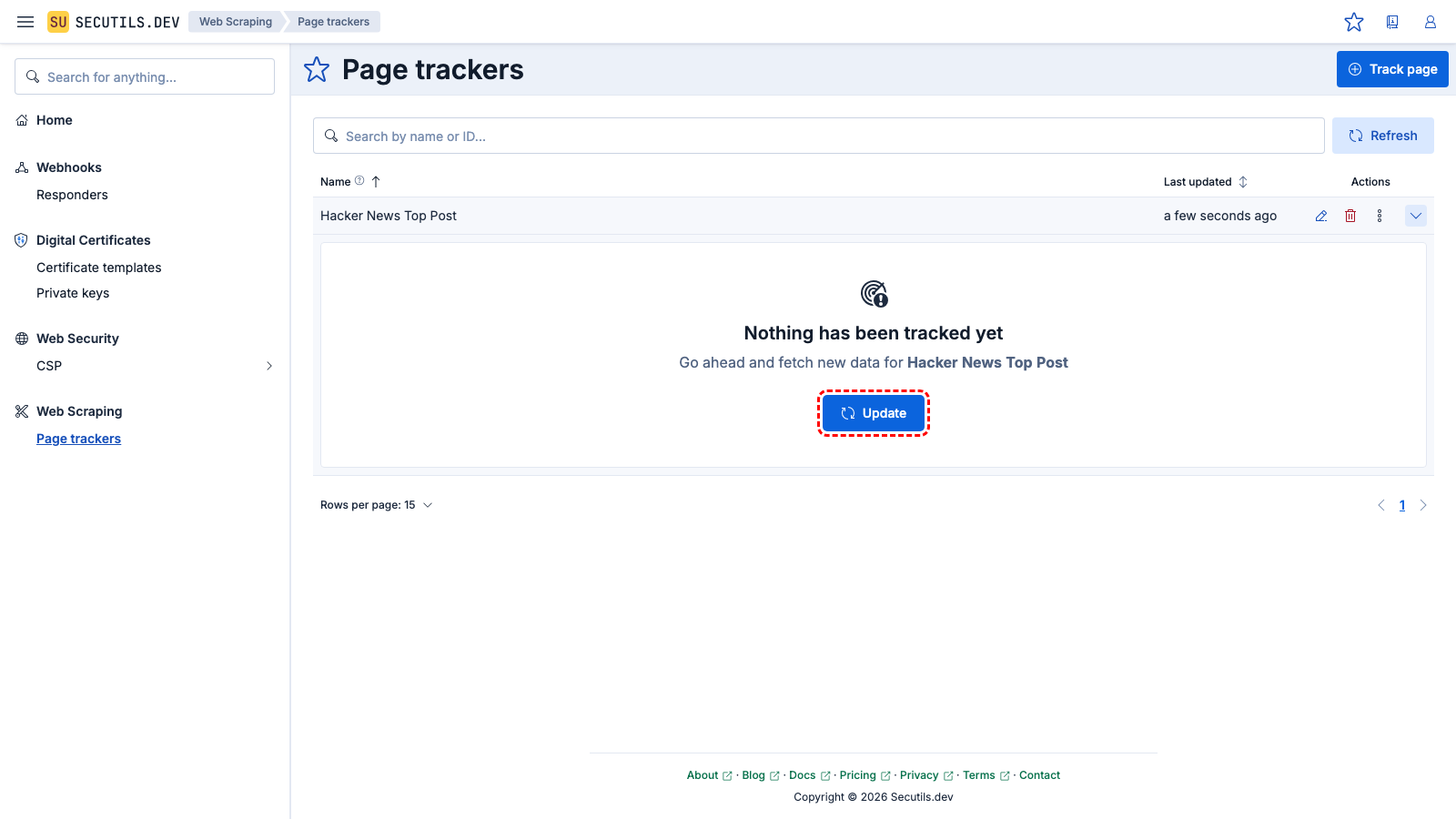
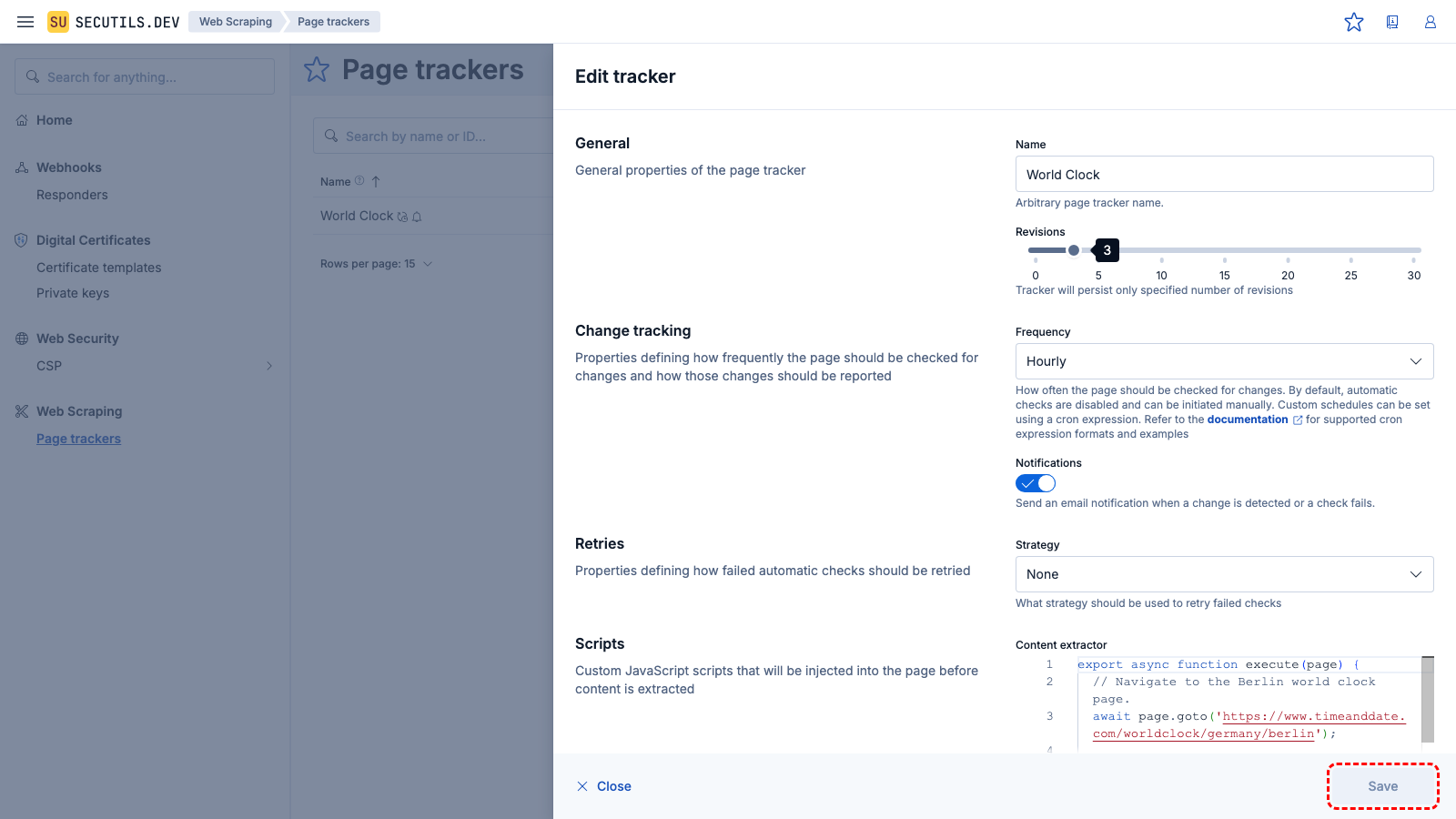
Expand the tracker's row and click the Update button to make the first snapshot of the web page content. After a few seconds, the tracker will fetch the current Berlin time and render a nice markdown with a link to a world clock website:
Berlin time is 01:02:03
With this configuration, the tracker will check the content of the web page every hour and notify you if any changes are detected.
Record a content extractor script
Instead of writing a content extractor script from scratch, you can record browser interactions using standard Playwright tools and import the recording into Secutils.dev. This is a great way to quickly get started, especially for scenarios that involve navigating through several pages or filling out forms.
Step 1: Record your interactions
Use any of these methods to record a Playwright scenario:
Option A: Playwright codegen (CLI)
npx playwright codegen https://your-target-site.com
This opens a browser window and the Playwright Inspector. Interact with the site as you normally would - the Inspector generates JavaScript code in real time. When done, click the copy button in the Inspector to copy the generated script.
Use --target=javascript-library to generate a plain script (without the test framework wrapper), which produces slightly cleaner output for import.
Option B: Chrome DevTools Recorder
- Open Chrome DevTools (F12).
- Go to the Recorder panel.
- Click Create recording, perform your interactions, then stop recording.
- Click Export recording → JSON.
Option C: Browser extensions
Several Chrome extensions can record Playwright scripts directly:
Step 2: Import into Secutils.dev
- Open the page tracker form (create new or edit existing).
- Right-click the
Content extractoreditor. - Select Import: Playwright recording or Import: Chrome DevTools recording from the context menu.
- Paste the recorded script (or JSON export) into the dialog and click Import.
The script is automatically transformed into the Secutils.dev extractor format - all browser setup/teardown boilerplate is stripped and the code is wrapped in the execute(page) function.
Step 3: Add a return statement
The imported script contains a TODO comment reminding you to add a return statement. This determines what content the tracker will store and monitor for changes. For example:
export async function execute(page) {
await page.goto('https://example.com/');
await page.getByRole('link', { name: 'Pricing' }).click();
// Return the content you want to track:
return await page.locator('.pricing-table').textContent();
}
Step 4: Debug and save
Use the Debug button to run the script and verify the extracted content before saving the tracker.
Track web page resources
You can also use the page tracker utility to detect and track resources of any web page. This functionality falls under the category of synthetic monitoring tools and helps ensure that the deployed application loads only the intended web resources (JavaScript and CSS) during its lifetime. If any unintended changes occur, which could result from a broken deployment or malicious activity, the tracker will promptly notify developers or IT personnel about the detected anomalies.
Additionally, security researchers who focus on discovering potential vulnerabilities in third-party web applications can use page trackers to be notified when the application's resources change. This allows them to identify if the application has been upgraded, providing an opportunity to re-examine it and potentially discover new vulnerabilities.
Extracting all page resources isn't as straightforward as it might seem, so it's recommended to use the utilities provided by Secutils.dev, as demonstrated in the examples in the following sections. Utilities return CSS and JS resource descriptors with the following interfaces:
/**
* Describes external or inline resource.
*/
interface WebPageResource {
/**
* Resource type, either 'script' or 'stylesheet'.
*/
type: 'script' | 'stylesheet';
/**
* The URL resource is loaded from.
*/
url?: string;
/**
* Resource content descriptor (size and digest), if available.
*/
content: WebPageResourceContent;
}
/**
* Describes resource content.
*/
interface WebPageResourceContent {
/**
* Resource content data.
*/
data: { raw: string } | { tlsh: string } | { sha1: string };
/**
* Describes resource content data, it can either be the raw content data or a hash such as Trend Micro Locality
* Sensitive Hash or simple SHA-1.
*/
size: number;
}
In this guide, you'll create a simple page tracker to track resources of the Hacker News:
| Name | |
| Content extractor | |
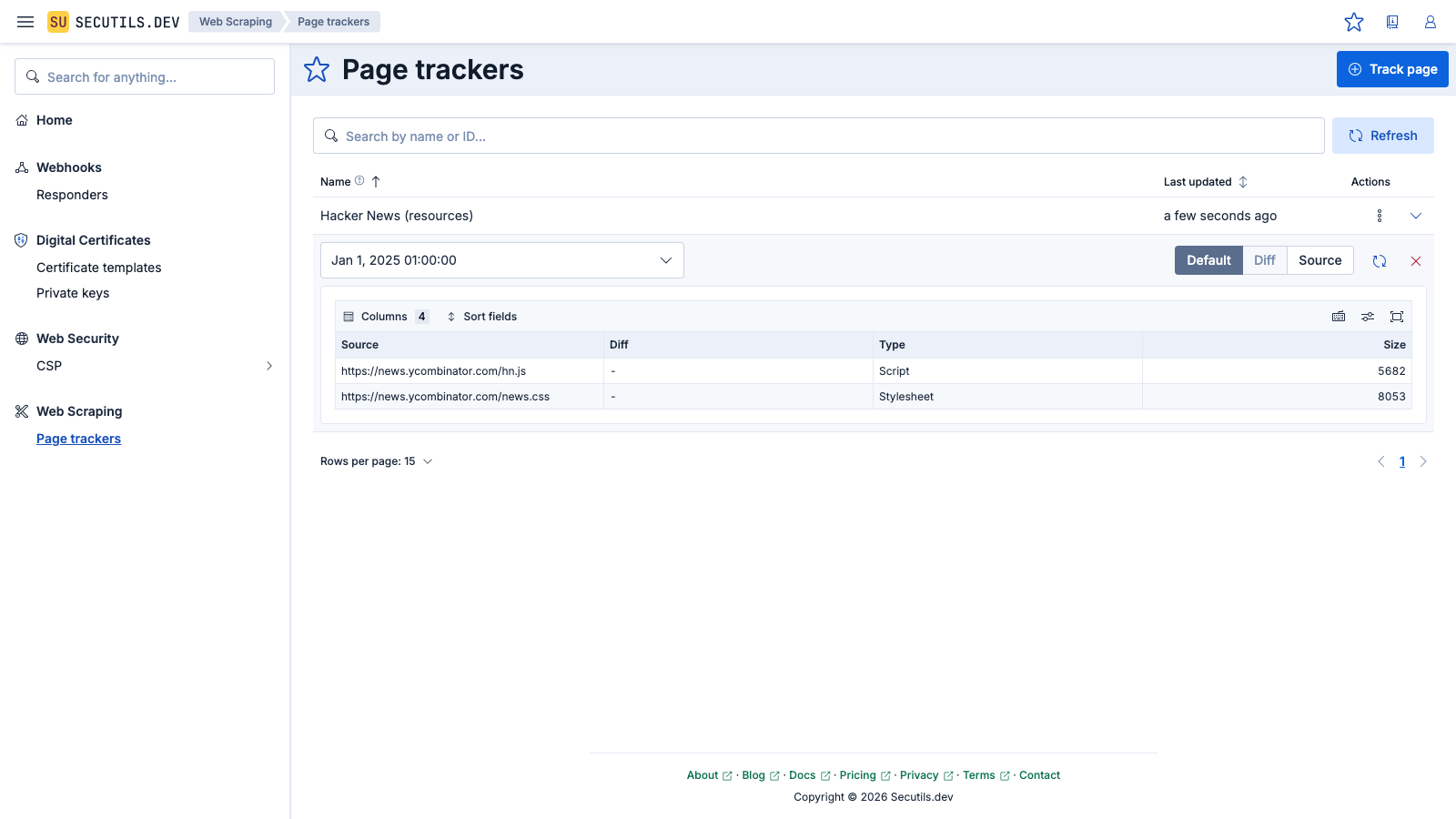
It's hard to believe, but as of the time of writing, Hacker News continues to rely on just a single script and stylesheet!
Filter web page resources
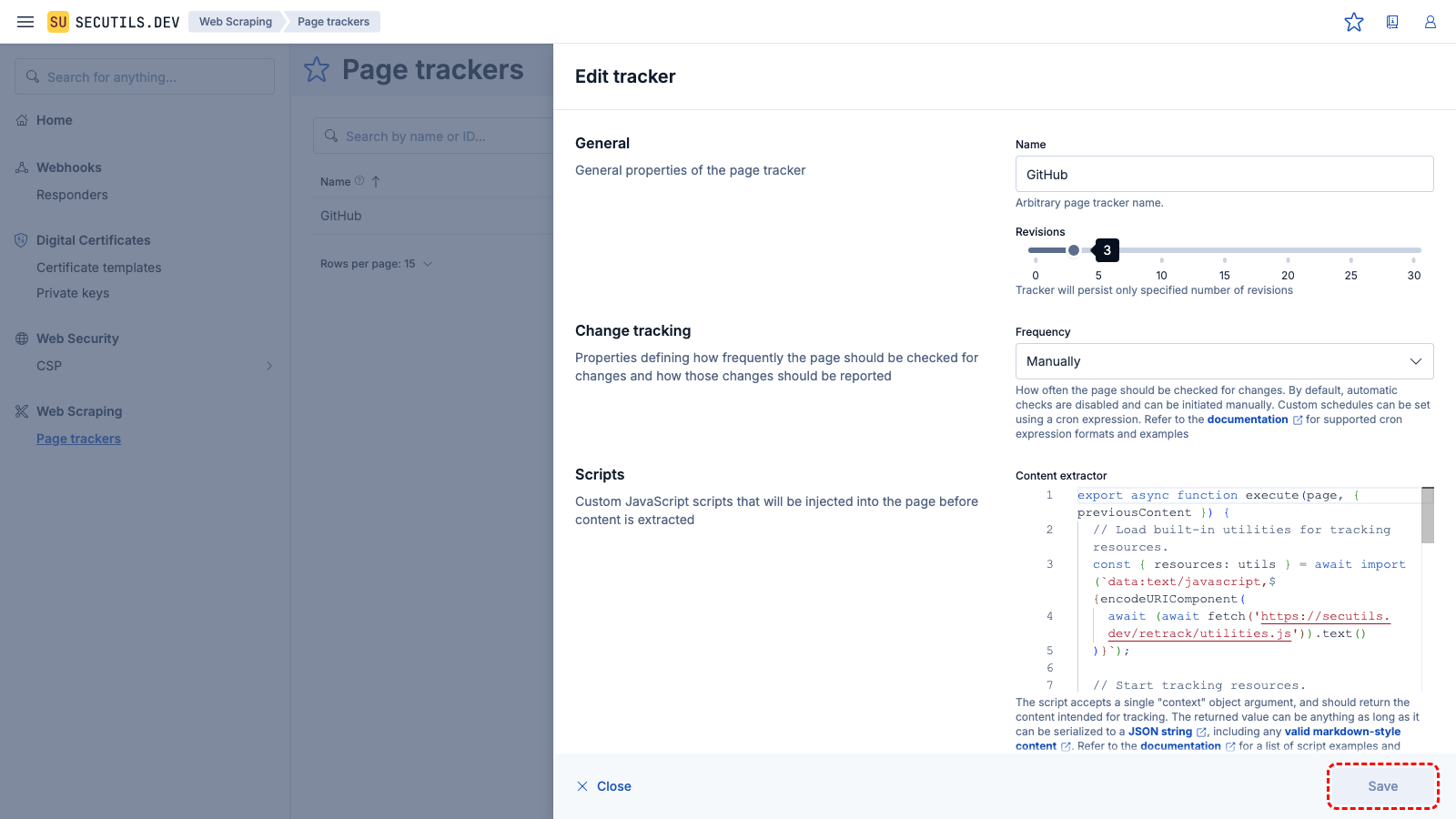
In this guide, you will create a page tracker for the GitHub home page and learn how to track only specific resources:
| Name | |
| Content extractor | |
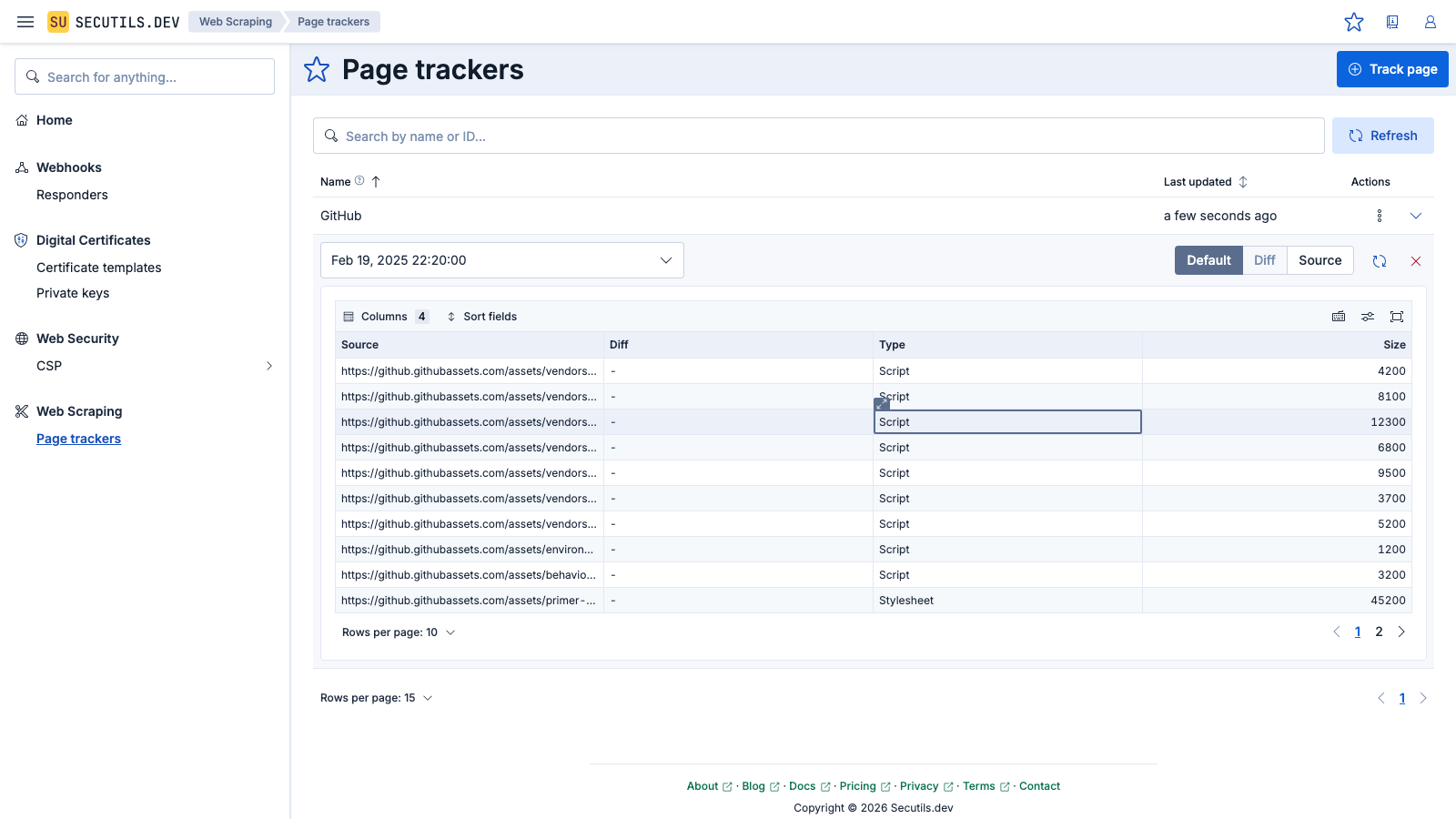
You'll notice that there are nearly 100 resources used for the GitHub home page! In the case of large and complex pages like this one, it's recommended to have multiple separate trackers, e.g. one per logical functionality domain, to avoid overwhelming the developer with too many resources and consequently changes they might need to track. Let's say we're only interested in "vendored" resources.
To filter out all resources that are not "vendored", edit the tracker and update the Content extractor script:
export async function execute(page, { previousContent }) {
// Load built-in utilities for tracking resources.
const { resources: utils } = await import(`data:text/javascript,${encodeURIComponent(
await (await fetch('https://secutils.dev/retrack/utilities.js')).text()
)}`);
// Start tracking resources.
utils.startTracking(page);
// Navigate to the target page.
await page.goto('https://github.com');
await page.waitForTimeout(1000);
// Stop tracking and return resources.
const allResources = await utils.stopTracking(page);
// Filter out all resources that are not "vendored".
const resources = {
scripts: allResources.scripts.filter((resource) => resource.url?.includes('vendors')),
styles: allResources.styles.filter((resource) => resource.url?.includes('vendors')),
};
// Format resources as a table,
// showing diff status if previous content is available.
return utils.formatAsTable(
previousContent
? utils.setDiffStatus(previousContent.original.source, resources)
: resources
);
};
Save the tracker and click the Update button to re-fetch web page resources. Once the tracker has re-fetched resources, only about half of the previously extracted resources will appear in the resources grid.
Detect changes in web page resources
In this guide, you will create several webhook responders that emulate JavaScript files and a simple HTML page, then set up a page tracker to detect changes in the resources loaded by that page across revisions.
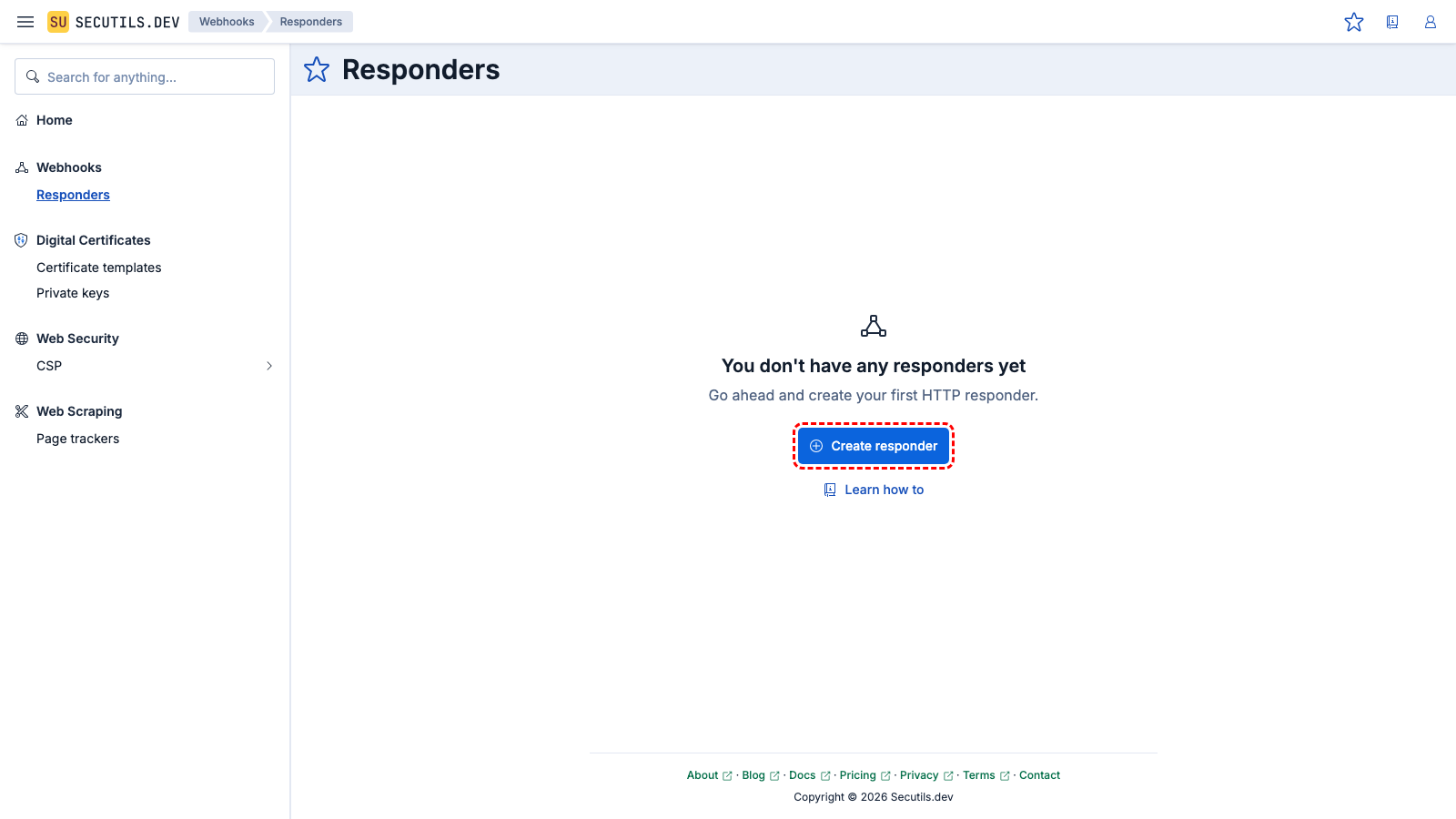
| Name | |
| Path | |
| Headers | |
| Body | |
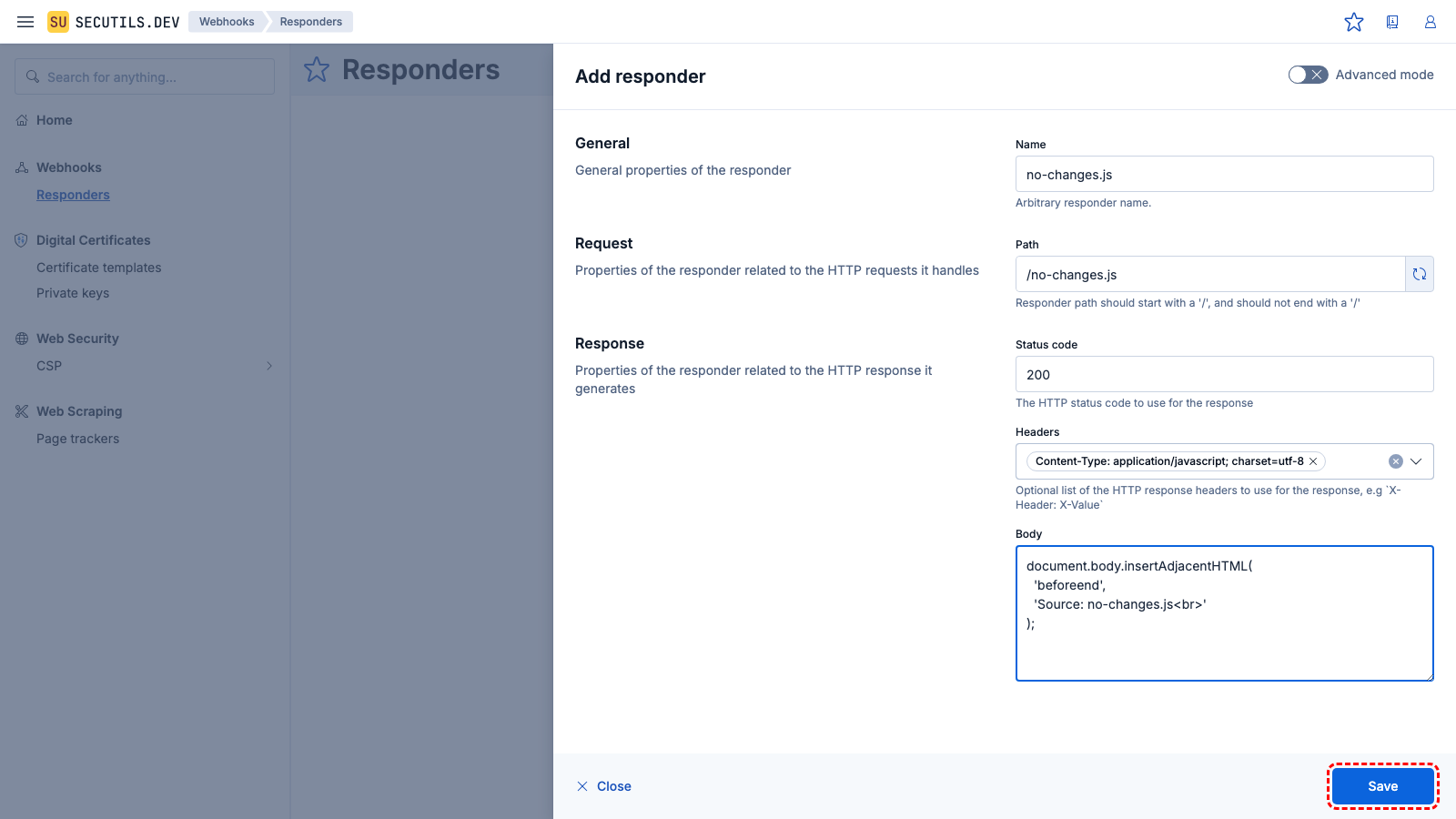
| Name | |
| Path | |
| Headers | |
| Body | |
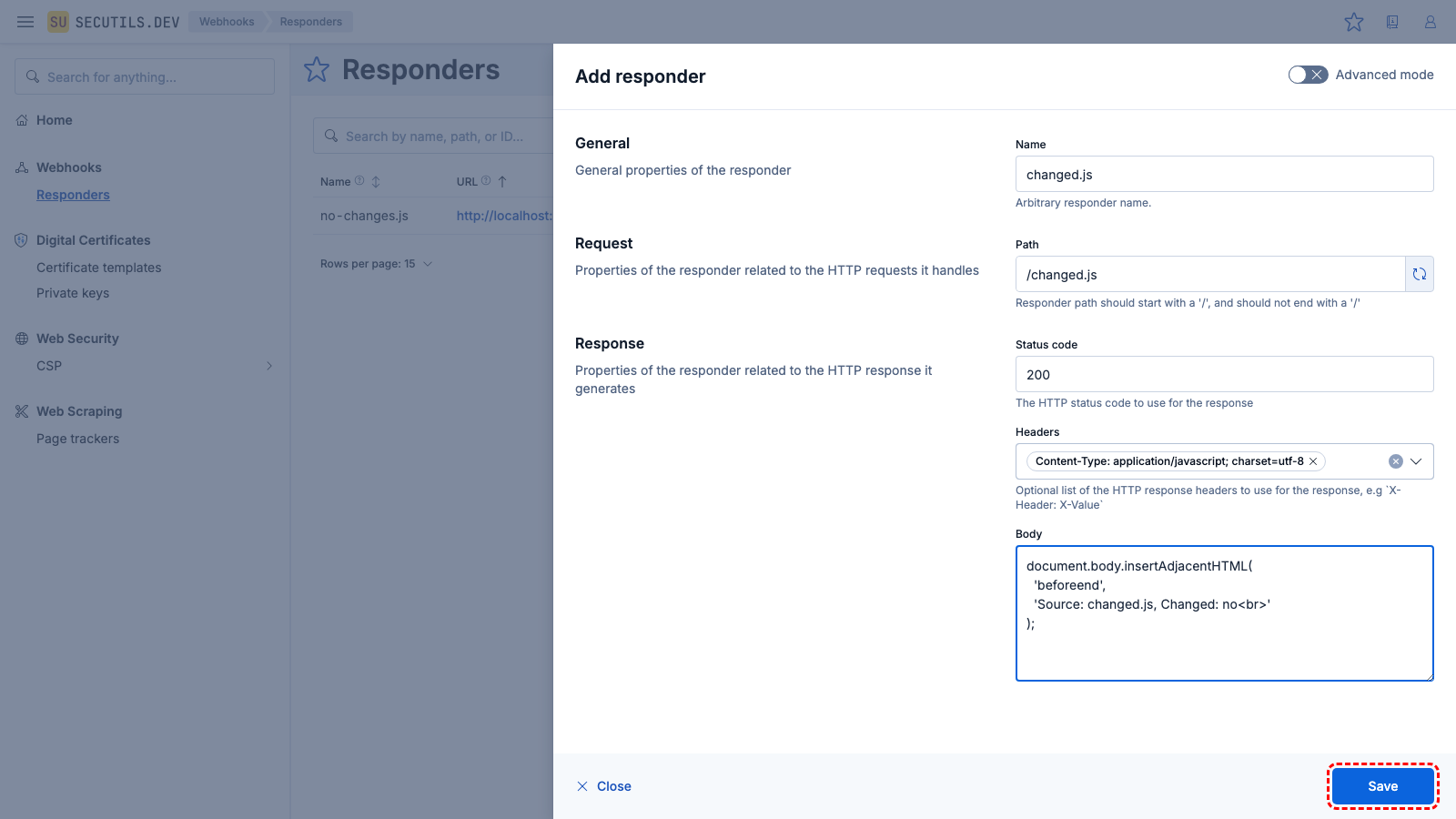
| Name | |
| Path | |
| Headers | |
| Body | |
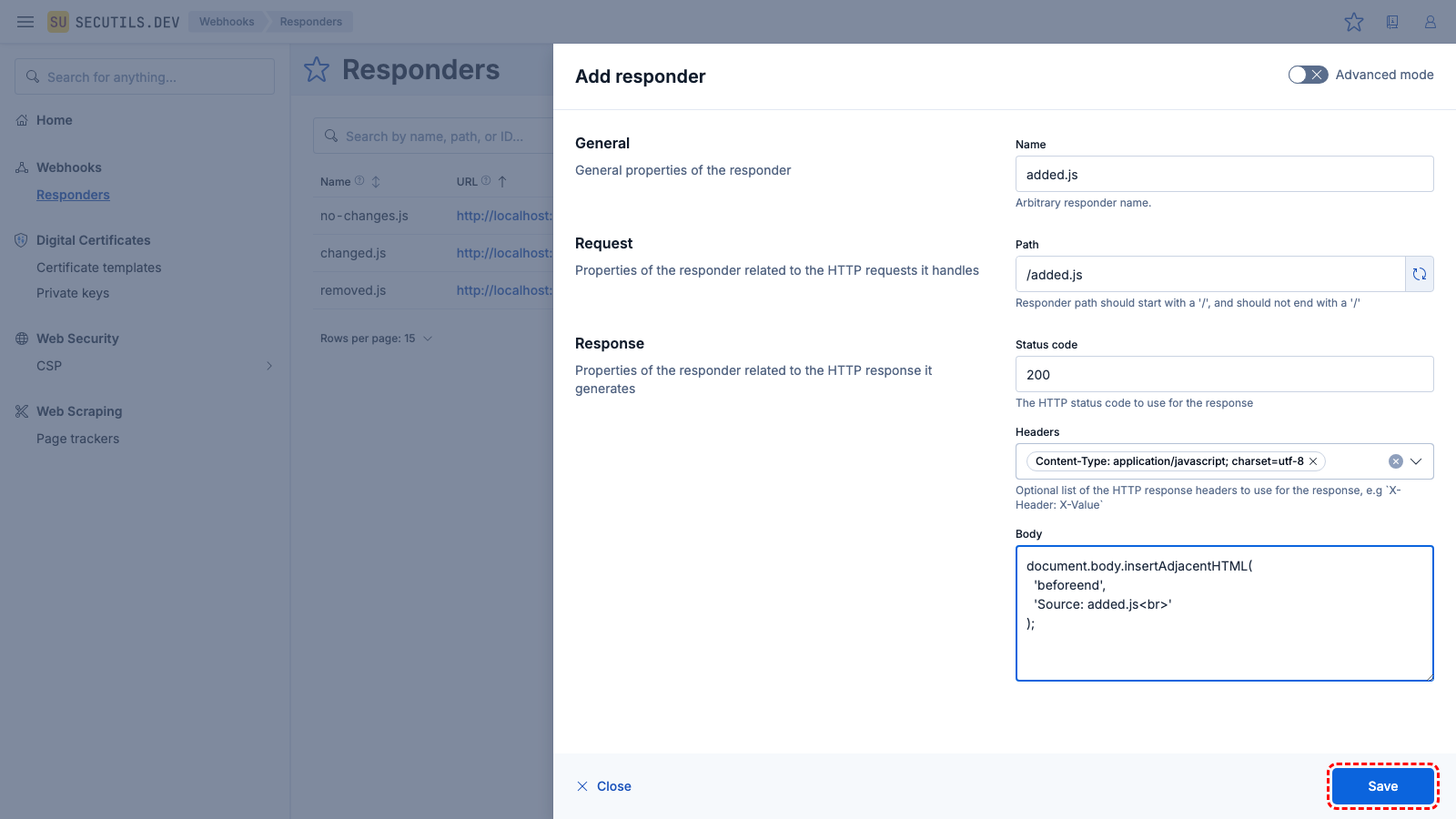
| Name | |
| Path | |
| Headers | |
| Body | |
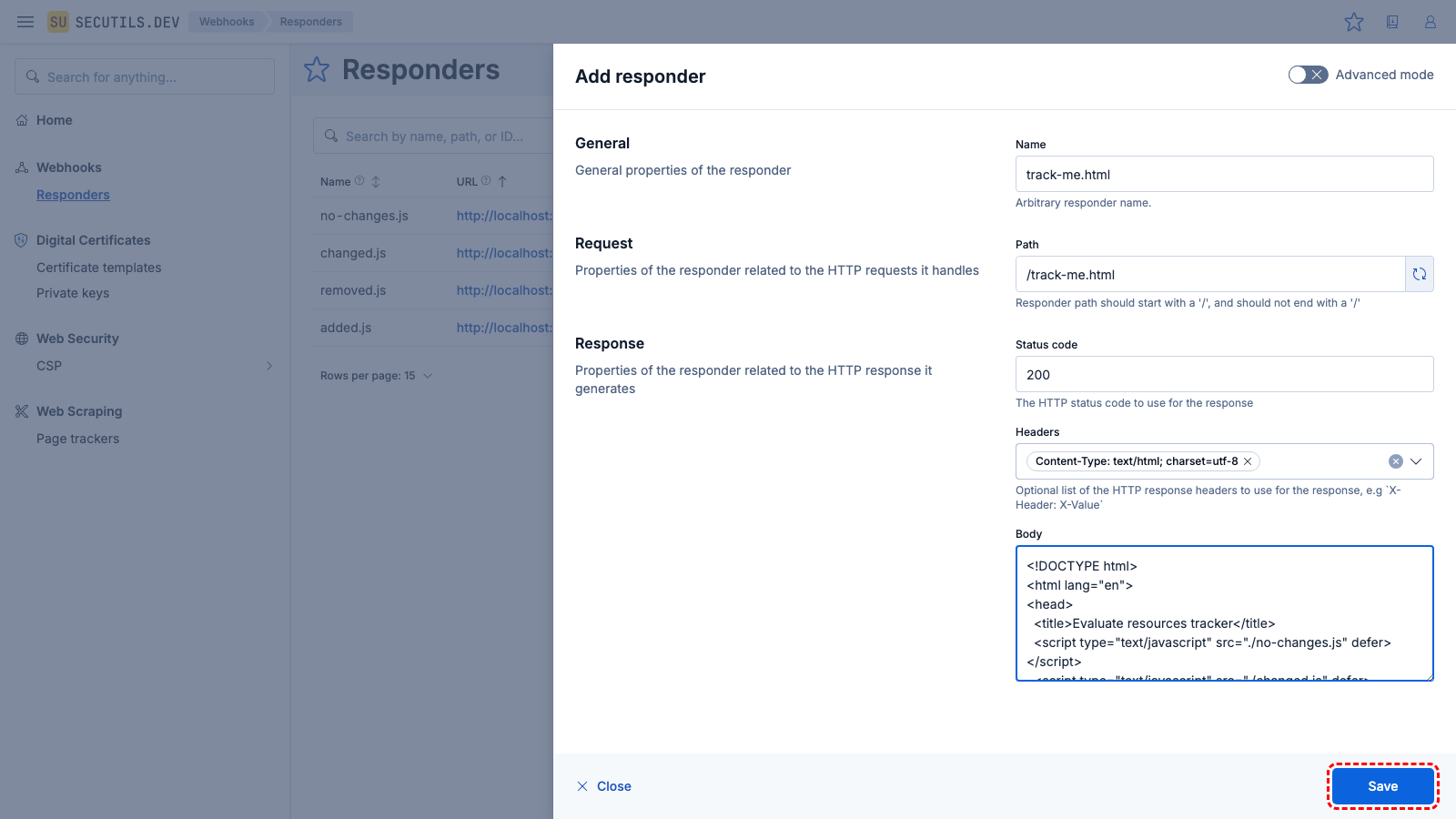
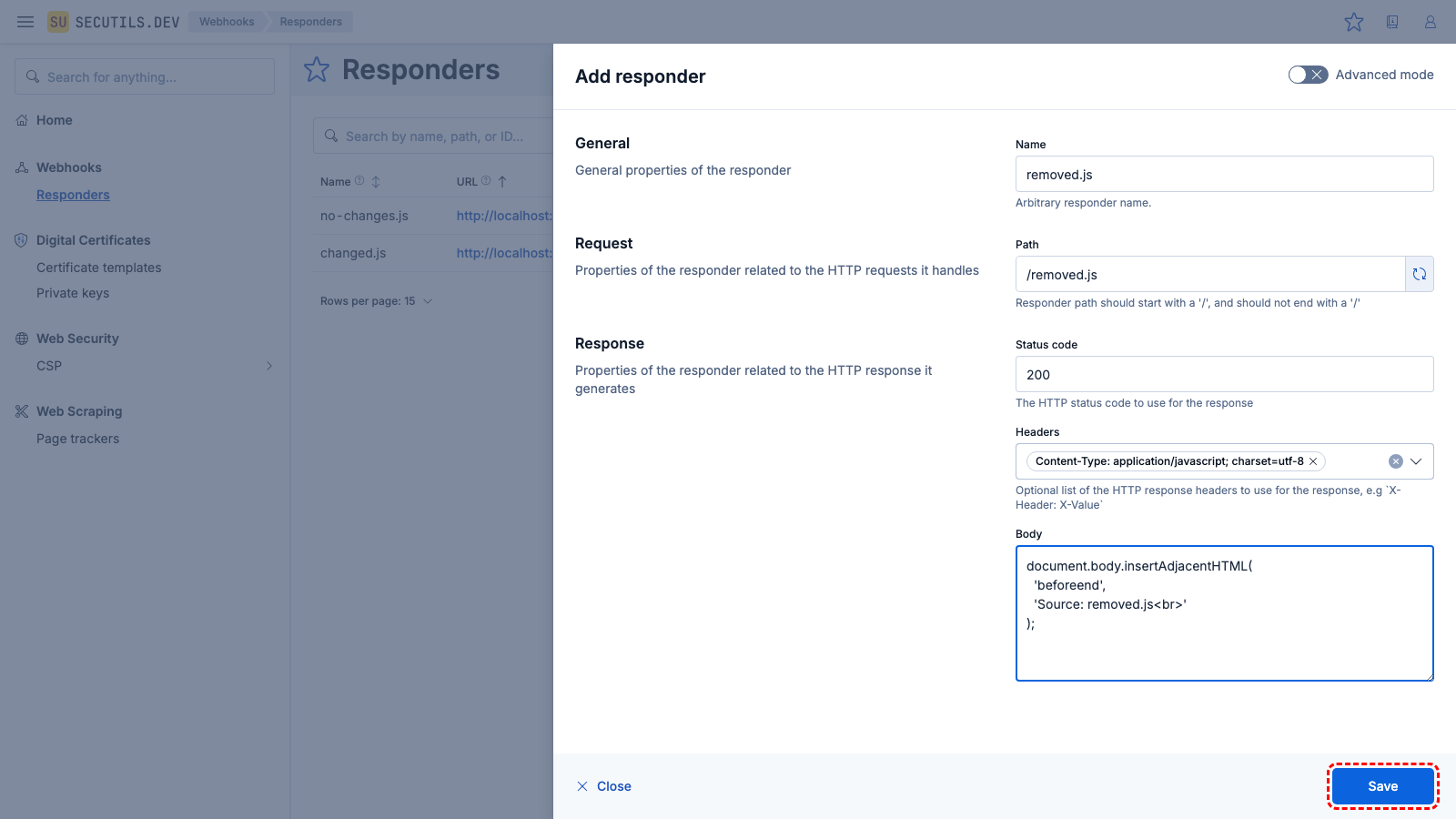
added.js) and click Save.| Name | |
| Path | |
| Headers | |
| Body | |
track-me.html responder and click Save.| Name | |
| Content extractor | |
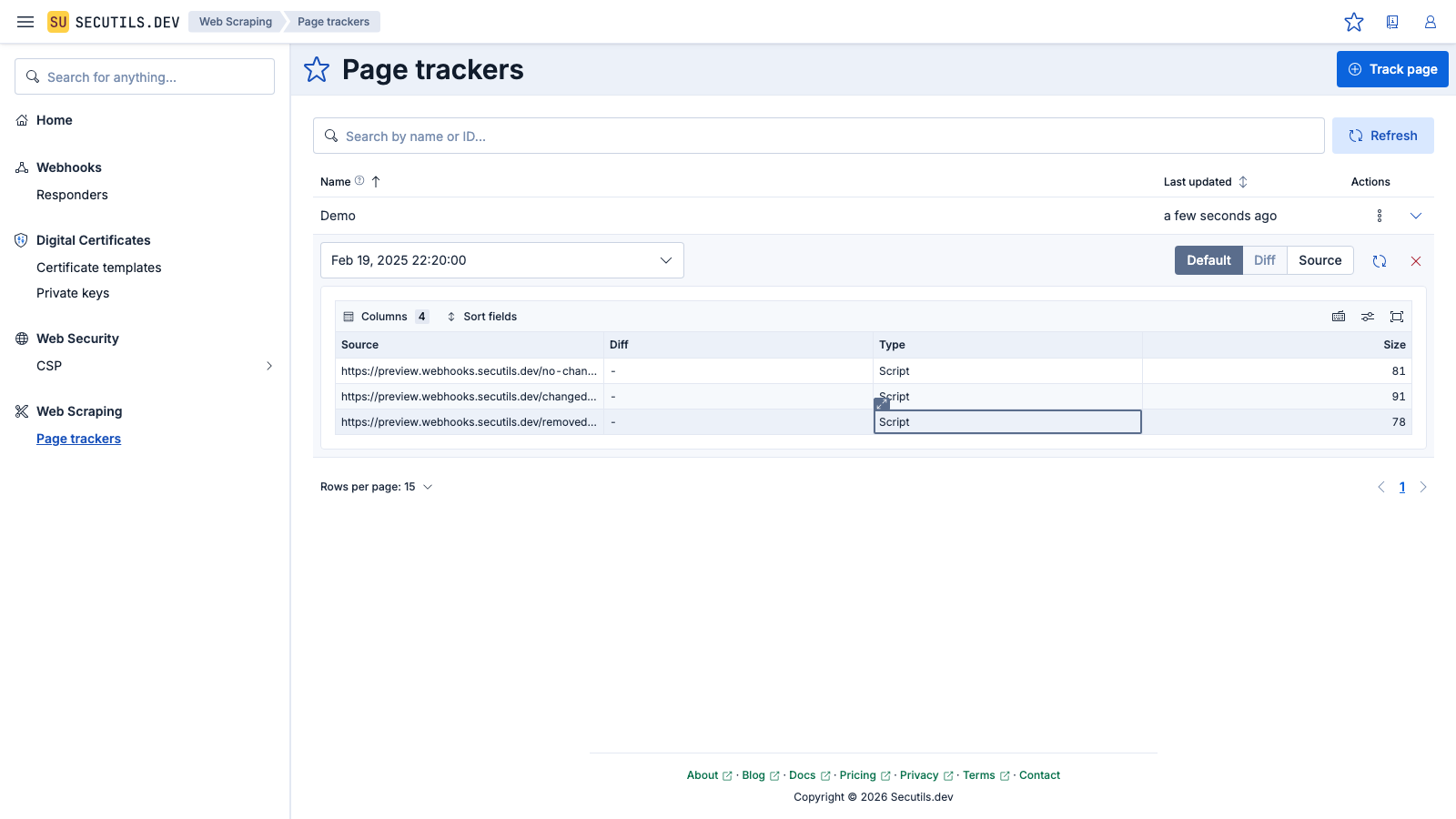
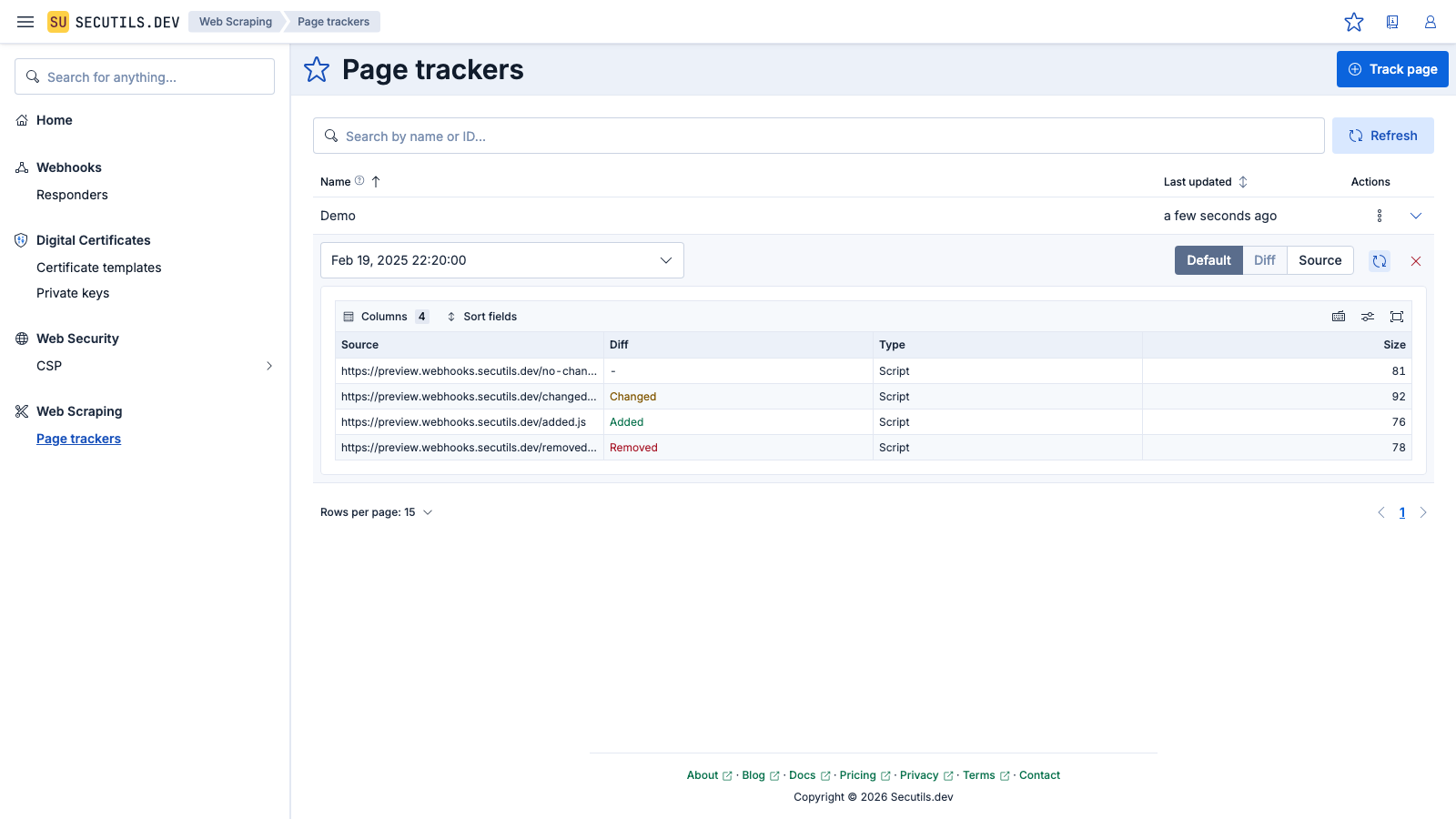
removed.js with added.js in track-me.html and update the body of changed.js - click Update again to see the diff statuses: Added, Changed, and Removed.You can configure the tracker with a schedule (e.g. Daily) and enable Notifications so that Secutils.dev automatically checks for resource changes and alerts you when they occur.
Debug a page tracker
Before saving a tracker you can use the built-in Debug mode to run the full extraction pipeline and inspect every detail - from the Playwright scenario execution to the final extracted result. This is useful for verifying that your content extractor script works correctly and produces the expected output.
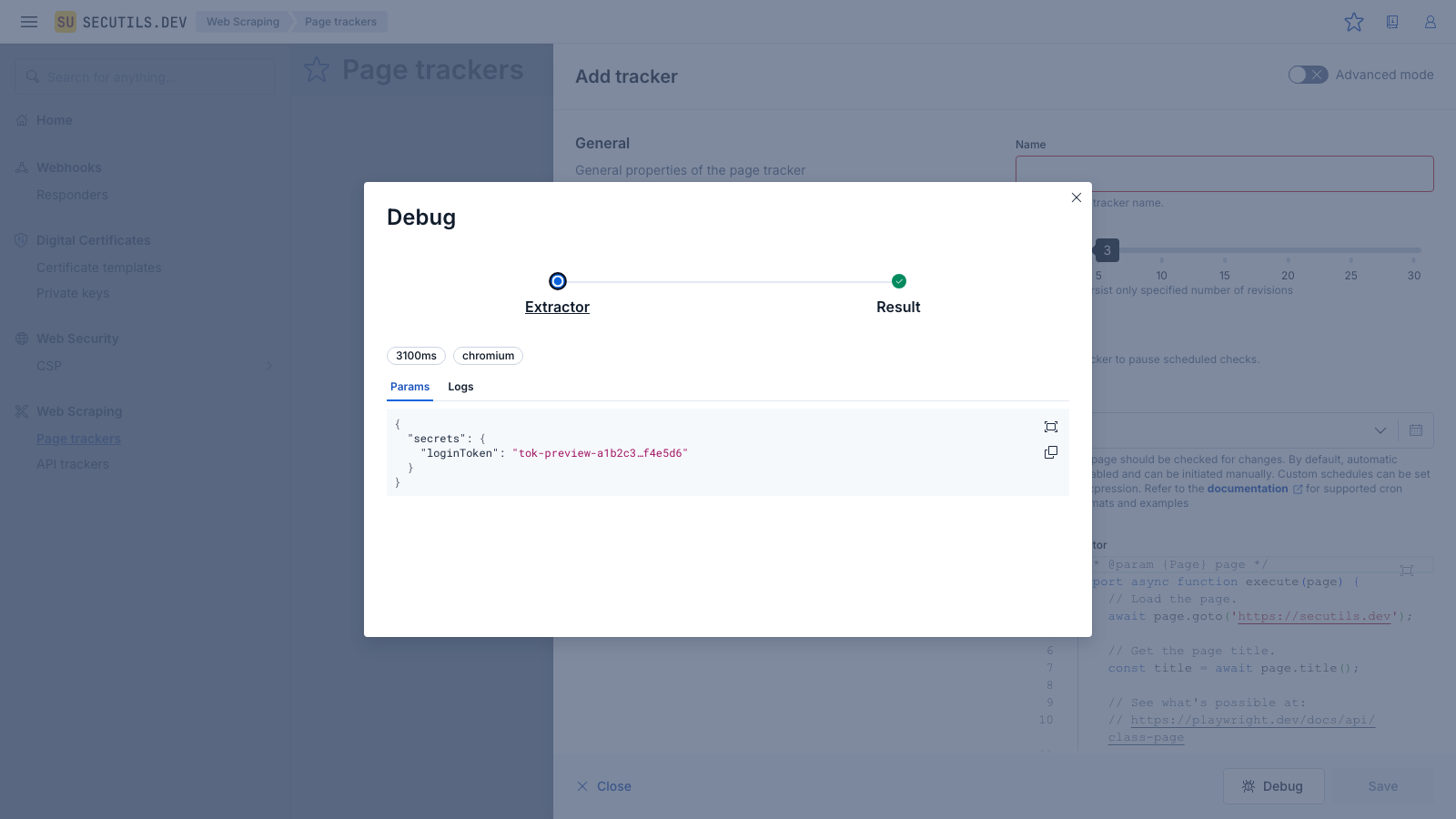
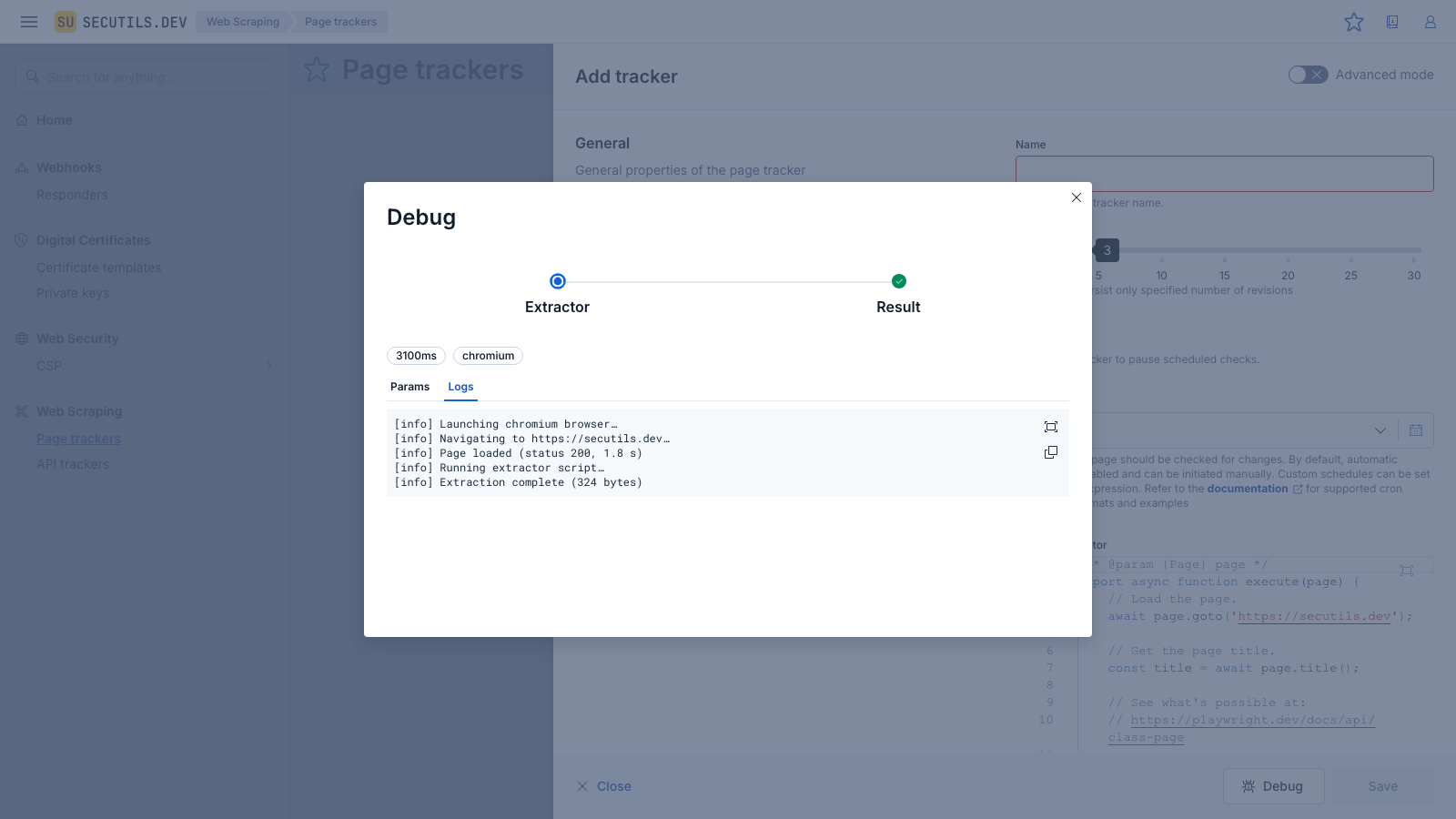
console.log calls from the extractor script and browser-side console output. This is helpful for diagnosing navigation issues or slow page loads.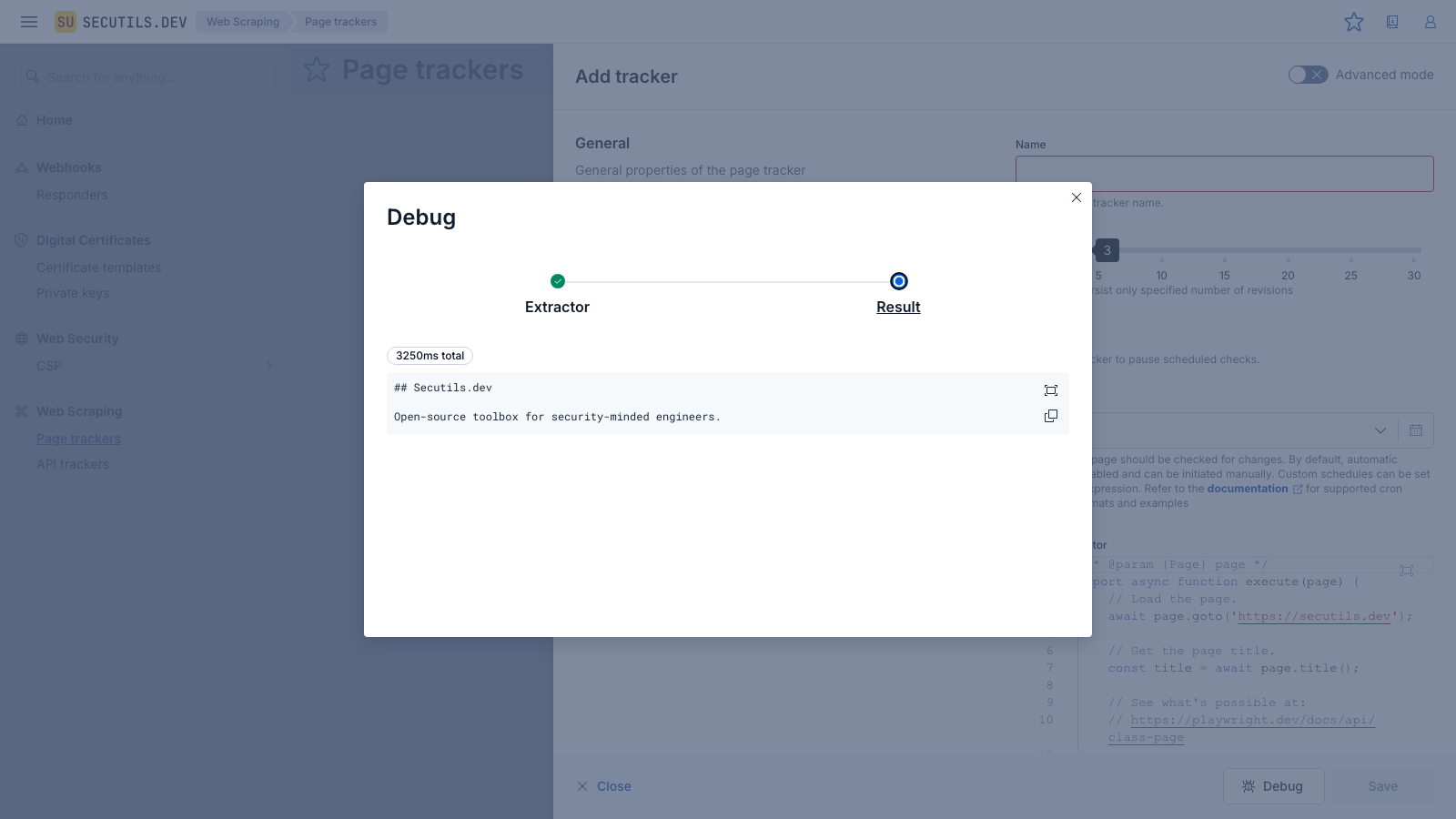
Automatic visual trace (Screenshots)
In debug mode, a screenshot is automatically captured after every significant Playwright action (goto, click, fill, type, press, check, uncheck, selectOption). These auto-trace screenshots create a visual storyboard of the script execution without any changes to the extractor script. You can also call page.screenshot() manually in the script - in debug mode the image is captured in-memory rather than written to disk.
All captured screenshots appear in the Screenshots tab in the Extractor step. Click any screenshot to view it in fullscreen. Screenshot labels (e.g., "after goto: https://example.com") describe the action that triggered the capture.
Screenshots are subject to a per-run size limit (5 MB by default). When the limit is reached, subsequent screenshots are silently skipped - the extraction still succeeds. Auto-trace screenshots use viewport-only captures to conserve the size budget.
The Debug button is available whenever a content extractor script is present - you don't need to save the tracker first. If the extraction fails, the Extractor step will be highlighted in red and the error message will be shown in the detail panel.
Browser engine
By default, page trackers use Chromium to run content extractor scripts. If the target page blocks automated Chromium browsers (e.g. via bot detection or browser fingerprinting), you can switch to Camoufox - a Firefox-based engine with enhanced anti-fingerprinting capabilities.
The browser engine setting is available in Advanced mode. Toggle the Advanced mode switch in the tracker form header to reveal the Browser engine selector in the Scripts section.
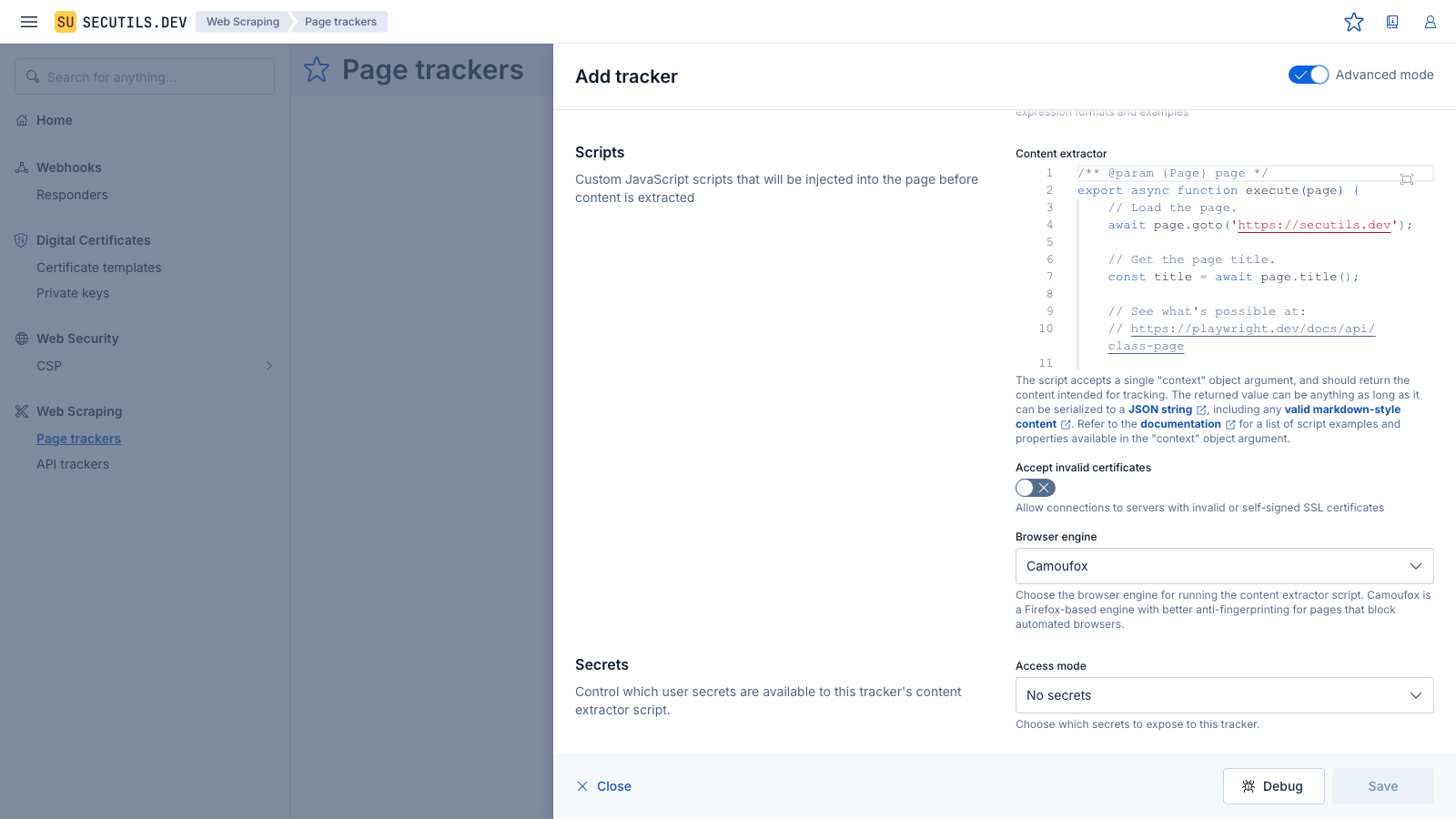
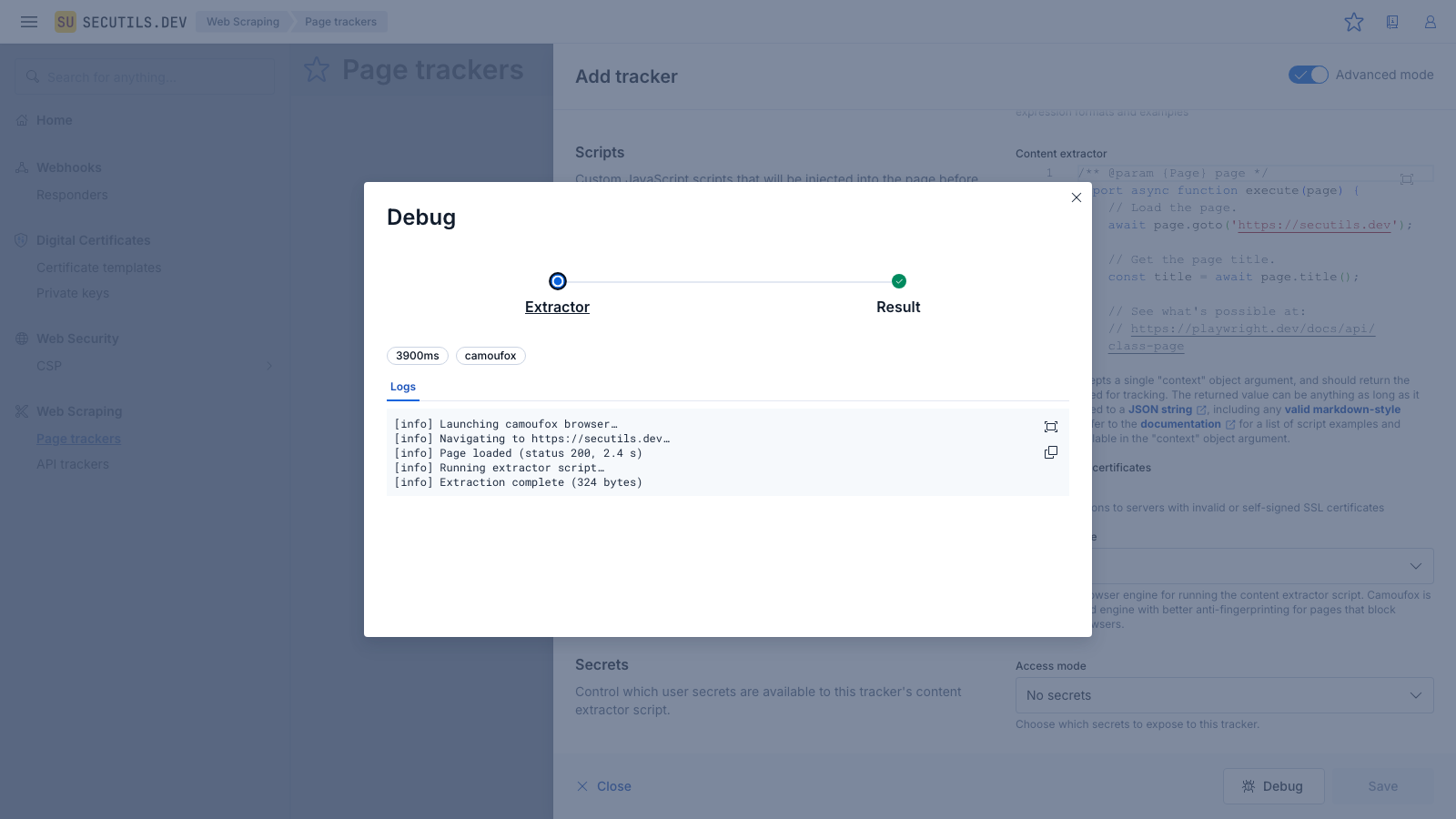
The selected engine applies to both scheduled checks and debug runs. Camoufox may be slower than Chromium for some pages due to the additional anti-fingerprinting measures. Use the Debug mode to compare extraction results and performance before choosing an engine.
View execution logs
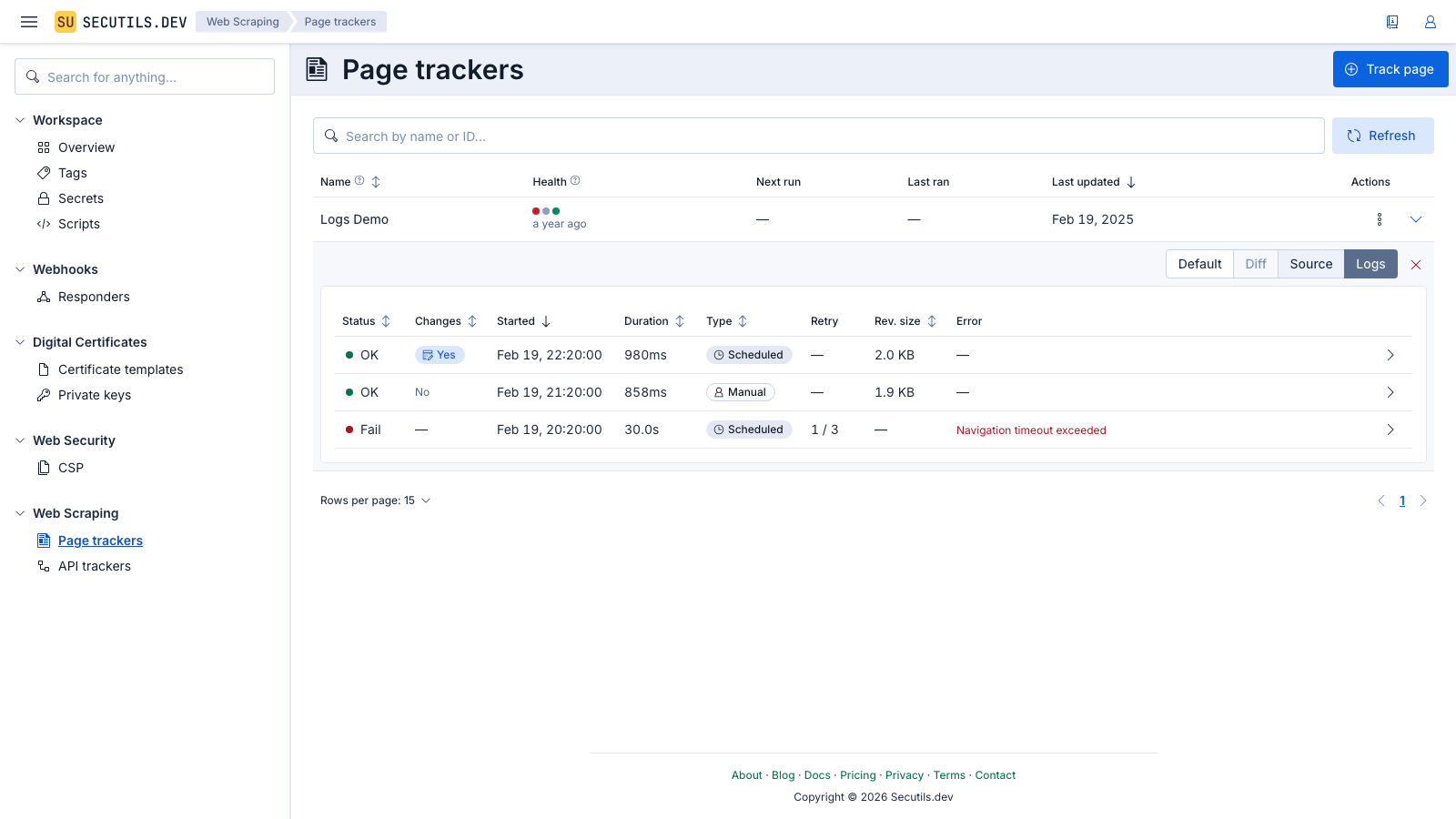
Every time a page tracker runs - whether manually or on a schedule - Secutils.dev records an execution log entry. You can use these logs to understand when the tracker ran, how long it took, whether it succeeded or failed, and what happened during each phase of execution.
To view the execution logs, expand the tracker row in the list and switch to the Logs view using the view mode toggle:
 |
|---|
The log table shows:
- Status - whether the execution succeeded or failed
- Started - when the execution began
- Duration - how long the execution took
- Type - whether it was a manual or scheduled run
- Retry - the retry attempt number, if applicable
- Revision size - the size of the stored revision data
- Error - the error message, if the execution failed
Each row can be expanded to reveal the execution phases - a detailed timeline of the steps the tracker performed (e.g. fetching data, extracting content, comparing with previous revision, persisting the result).
The Health column in the tracker list provides a quick at-a-glance summary of recent execution results, showing colored dots for the last several runs (green for success, red for failure).
To clear all execution logs for a tracker, click the Clear logs button (cross icon) while in the Logs view mode.
Annex: Content extractor script examples
In this section, you can find examples of content extractor scripts that extract various content from web pages. Essentially, the script defines a function with the following signature:
/**
* Content extractor script that extracts content from a web page.
* @param page - The Playwright Page object representing the web page.
* See more details at https://playwright.dev/docs/api/class-page.
* @param context.previousContent - The context extracted during
* the previous execution, if available.
* @param context.params.secrets - User secrets (key-value pairs).
* Available when secrets access is enabled in the tracker settings.
* @returns {Promise<unknown>} - The extracted content to be tracked.
*/
export async function execute(
page: Page,
context: {
previousContent?: { original: unknown };
params?: { secrets?: Record<string, string> };
}
)
To make secrets available to your extractor script, open the tracker's edit form and set the Secrets → Access mode to All secrets or Selected secrets. The decrypted secrets will then be available as context.params.secrets. Manage your secrets in Workspace → Secrets. Example: const token = context.params.secrets.MY_TOKEN;
Track markdown-style content
The script can return any valid markdown-style content that Secutils.dev will happily render in preview mode.
export async function execute() {
return `
## Text
### h3 Heading
#### h4 Heading
**This is bold text**
*This is italic text*
~~Strikethrough~~
## Lists
* Item 1
* Item 2
* Item 2a
## Code
\`\`\` js
const foo = (bar) => {
return bar++;
};
console.log(foo(5));
\`\`\`
## Tables
| Option | Description |
| -------- | ------------- |
| Option#1 | Description#1 |
| Option#2 | Description#2 |
## Links
[Link Text](https://secutils.dev)
## Emojies
:wink: :cry: :laughing: :yum:
`;
}
Track API response
You can use page tracker to track API responses as well (until dedicated API tracker utility is released). For instance, you can track the response of the JSONPlaceholder API:
Ensure that the web page from which you're making a fetch request allows cross-origin requests. Otherwise, you'll get an error.
export async function execute() {
const {url, method, headers, body} = {
url: 'https://jsonplaceholder.typicode.com/posts',
method: 'POST',
headers: {'Content-Type': 'application/json; charset=UTF-8'},
body: JSON.stringify({title: 'foo', body: 'bar', userId: 1}),
};
const response = await fetch(url, {method, headers, body});
return {
status: response.status,
headers: Object.fromEntries(response.headers.entries()),
body: (await response.text()) ?? '',
};
}
Use previous content
In the content extract script, you can use the context.previousContent.original property to access the content extracted during the previous execution:
export async function execute(page, { previousContent }) {
// Update counter based on the previous content.
return (previousContent?.original ?? 0) + 1;
}
Use external content extractor script
Sometimes, your content extractor script can become large and complicated, making it hard to edit in the Secutils.dev UI. In such cases, you can develop and deploy the script separately in any development environment you prefer. Once the script is deployed, you can just use URL as the script content :
// This code assumes your script exports a function named `execute` function.
https://secutils-dev.github.io/secutils-sandbox/content-extractor-scripts/markdown-table.js
You can find more examples of content extractor scripts at the Secutils.dev Sandbox repository.
Annex: Custom cron schedules
Custom cron schedules are available only for Pro subscription users.
In this section, you can learn more about the supported cron expression syntax used to configure custom tracking schedules. A cron expression is a string consisting of six or seven subexpressions that describe individual details of the schedule. These subexpressions, separated by white space, can contain any of the allowed values with various combinations of the allowed characters for that subexpression:
| Subexpression | Mandatory | Allowed values | Allowed special characters |
|---|---|---|---|
Seconds | Yes | 0-59 | * / , - |
Minutes | Yes | 0-59 | * / , - |
Hours | Yes | 0-23 | * / , - |
Day of month | Yes | 1-31 | * / , - ? |
Month | Yes | 0-11 or JAN-DEC | * / , - |
Day of week | Yes | 1-7 or SUN-SAT | * / , - ? |
Year | No | 1970-2099 | * / , - |
Following the described cron syntax, you can create almost any schedule you want as long as the interval between two consecutive checks is longer than 10 minutes. Below are some examples of supported cron expressions:
| Expression | Meaning |
|---|---|
0 0 12 * * ? | Run at 12:00 (noon) every day |
0 15 10 ? * * | Run at 10:15 every day |
0 15 10 * * ? | Run at 10:15 every day |
0 15 10 * * ? * | Run at 10:15 every day |
0 15 10 * * ? 2025 | Run at 10:15 every day during the year 2025 |
0 0/10 14 * * ? | Run every 10 minutes from 14:00 to 14:59, every day |
0 10,44 14 ? 3 WED | Run at 14:10 and at 14:44 every Wednesday in March |
0 15 10 ? * MON-FRI | Run at 10:15 from Monday to Friday |
0 11 15 8 10 ? | Run every October 8 at 15:11 |
To assist you in creating custom cron schedules, Secutils.dev lists five upcoming scheduled times for the specified schedule:
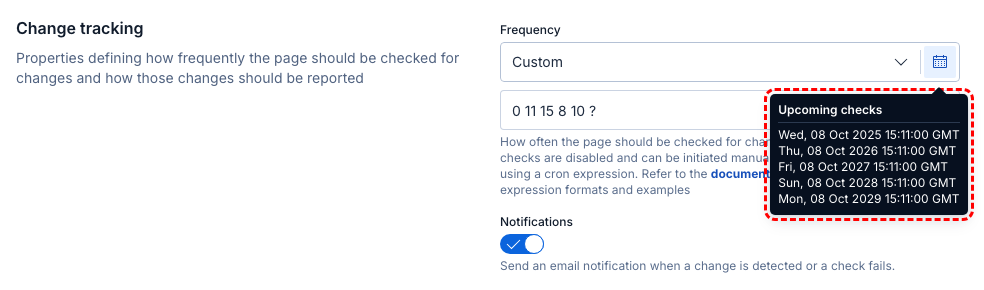 |
|---|